Il termine GUID sta per “Globally Unique Identifier”. Il suo scopo è quello di fornirci un identificativo univoco indipendentemente dal sistema che lo ha generato. La probabilità di avere due GUID generati con lo stesso valore è quasi prossima allo zero.
In SQL Server è rappresentato un tipo di dato binario a 16 byte chiamato anche UNIQUEIDENTIFIER. La caratteristica principale del tipo di dato GUID è di essere globalmente univoco tra le tabelle di uno stesso database, ma anche tra database diversi e addirittura tra diversi server.
Un valore GUID può essere generato in molti modi diversi. Tra le modalità più note troviamo l’utilizzo di numeri Random, sequenze generate da Time Clock, oppure basate sull’uso dell’indirizzo MAC delle schede di rete.
Si stima che utilizzando meccanismi come quelli sopra elencati si possa raggiungere un totale di circa 10^38 combinazioni di GUID diversi, una cifra decisamente soddisfacente per garantire univocità del valore ottenuto.
In SQL Server le funzioni che permettono di creare un GUID sono NEWID() e NEWSEQUENTIALID().
Ecco un esempio di come creare una tabella che utilizzi un GUID come chiave primaria:
CREATE TABLE EnglishStudents1 ( Id UNIQUEIDENTIFIER PRIMARY KEY deafult NEWID() ,StudentName VARCHAR(50) ) GO
Il vantaggio principale nell'utilizzare un GUID come chiave primaria di una tabella risiede nella possibilità di fare il merge di più tabelle (dello stesso database ma soprattutto di database o server diversi), senza pericolo di infrangere il vincolo di univocità della chiave primaria.
Facciamo un esempio per chiarire il concetto.
Supponiamo di avere 2 tabelle studenti memorizzate su 2 database diversi.

Ora supponiamo di voler creare una nuova tabella Studenti che contenga tutti i valori delle due tabelle precedenti:
USE EngDB GO CREATE TABLE Students ( Id INT PRIMARY KEY ,StudentName NVARCHAR(50) ) GO INSERT INTO Students SELECT * FROM EngDB.dbo.EnglishStudents UNION ALL SELECT * FROM MatchDB.dbo.MathStudents
Andremo inevitabilmente incontro ad un errore di questo tipo:

Stiamo infatti violando il vincolo di univocità della chiave primaria. Ecco che l’utilizzo di un GUID avrebbe permesso di fare il merge delle due tabelle senza andare incontro a questo tipo di problema.
Un altro vantaggio nell’utilizzo del GUID è che, essendo generato da sistema e non da un essere umano, non ha un significato facilmente intuibile e questo aspetto può tornare utile quando per esempio si creano delle interfacce pubbliche come gli URL:
- Utilizzando un classico id numerico come nell’URL
https://www.example.com/customer/100/ci fa capire che ci stiamo riferendo al cliente con id 100 e verosimilmente ci sarà anche un cliente 101, 102 e così via. - Viceversa usando un GUID come nell’URL
https://www.example.com/customer/F4AB02B7-9D55-483D-9081-CC4E3851E851/rende chiaramente molto meno informativa (e quindi più sicura) l’interfaccia.
A prima vista sembrerebbe che l’utilizzo di un tipo di dato come GUID porti con sé solo dei vantaggi aggiuntivi rispetto al classico utilizzo di un id INT. Tuttavia non è assolutamente cosi, anzi esistono diversi svantaggi, per cui occorre ponderare accuratamente l’opportunità o meno di utilizzare un GUID.
Vantaggi e svantaggi di GUID
Innanzitutto GUID utilizza 16 bytes di memoria contro i 4 bytes di INT e gli 8 bytes di BIGINT. Tutto ciò, rapportato a grandi moli di dati, fa una notevole differenza sulla quantità di memoria occupata. Una tabella a singola colonna con 1 milione di record occupa circa 3.8MB usando il tipo di dato INT e invece occupa 15.26 MB usando GUID. Una differenza notevole per una sola tabella.

Ci sono inoltre ulteriori considerazioni da dover tenere presente.
Generalmente l’utilizzo di INT o BIGINT come chiavi primarie è molto più efficiente a livello di prestazioni.
Vediamo la tabella seguente:
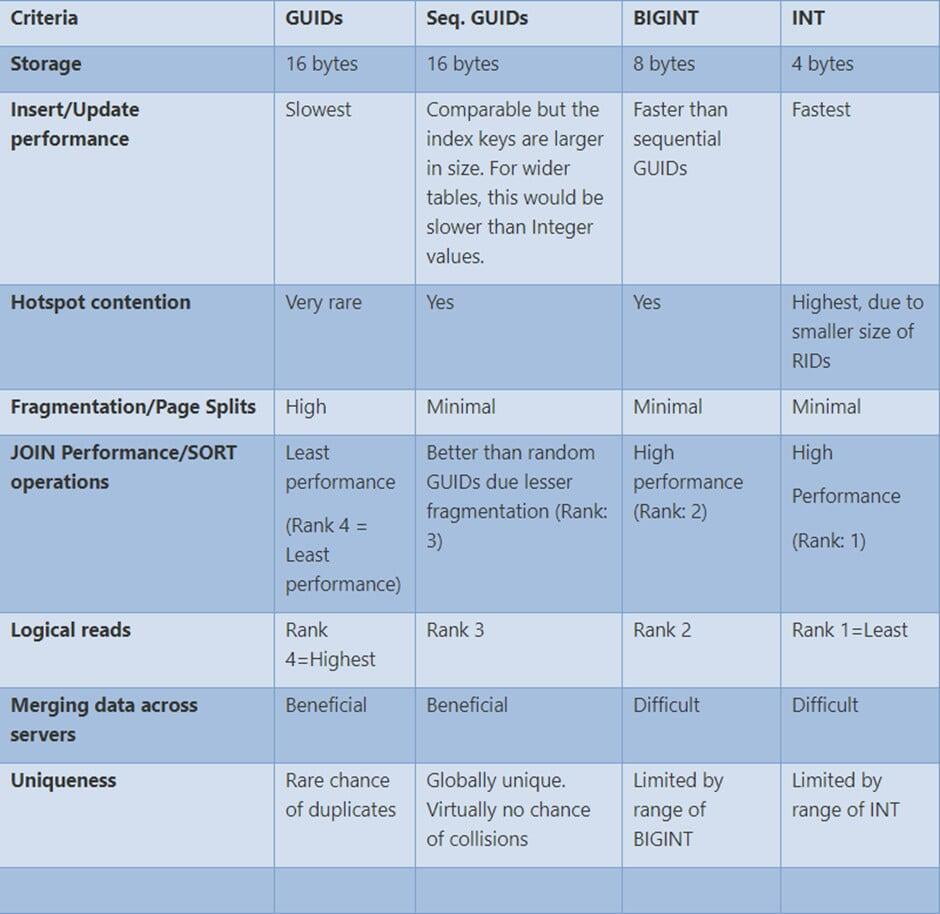
Notiamo come l’utilizzo di GUID sia assolutamente sconsigliato su ambienti con molte query che fanno uso pesante di join e soprattutto è sconsigliato se la colonna GUID viene usata come clustering key.
In alcuni casi si può adottare anche un approccio ibrido. Le tabelle, in questo modo, contengono sia una colonna di tipo INT come chiave primaria auto incrementante che una colonna di tipo GUID. La colonna GUID può essere utilizzata per identificare univocamente su sistemi distribuiti la riga della tabella, mentre la colonna INT può essere usata per le queries, per gli ordinamenti e per rendere comprensibile a livello umano il significato.
Per concludere, salvo necessità specifiche di avere una chiave assolutamente unica (distribuzione di database su server diversi, operazioni di merge di records da diversi database), l’utilizzo della classica chiave primaria (INT) ha maggiori vantaggi di performance, di spazio occupato, di frammentazione degli indici e indicizzazione stessa.
di Matteo Dal Bianco, pubblicato l'8 novembre 2019
