I sistemi informativi oggi sono la spina dorsale di un’azienda. I dati aziendali vengono governati da sistemi che li elaborano per ottenere informazioni, utilizzate successivamente per prendere le decisioni operative.
Nel corso degli anni è sempre più maturata l’esigenza di far convergere i dati all'interno di un unico sistema in grado di combinare dati relazionali e non relazionali, provenienti da fonti diverse, al fine di supportare le esigenze e gli scenari di business in cui le aziende hanno deciso di operare. C’è quindi bisogno di una piattaforma dati unificata, iper-convergente e in grado di superare i limiti imposti dai differenti tipi trattati.
Proprio con questa necessità di rispondere alle esigenze di business del mercato, dopo 25 anni dal lancio della prima versione di SQL Server (nel 1993 per Windows NT) Microsoft, sul finire del 2018, annuncia l’uscita dell’ultima versione del ben noto database relazionale: SQL Server 2019.
La nuova versione di SQL Server si contraddistingue per essere disponibile sia per ambiente Linux, sia per Windows e ha il supporto per la tecnologia containers Docker e Kubernetes.

Vediamo subito quali sono le novità più significative introdotte da questa nuova versione.
Gruppi di disponibilità Always on
Microsoft ha introdotto Always On Availability Groups già a partire da Sql Server 2012 e ha fatto continui miglioramenti nelle successive release. Tuttavia, una delle funzionalità di cui i DBA lamentavano maggiormente la mancanza, in questa tecnologia che permette di replicare su più server molteplici copie di database per poter garantire una continua disponibilità del servizio, è il supporto per i database di sistema MSDB e Master, i quali contengono importanti file di log dell’istanza e degli Agent jobs, schedulazioni e notifiche varie. Per supplire a questa mancanza finora si doveva ricorrere ad applicativi terzi o script powershell. Con SQL Server 2019, Microsoft ha finalmente colmato questa lacuna.
SQL Server 2019 aumenta il numero massimo di repliche sincrone a 5. Il numero massimo era di 3 in SQL Server 2017. Sono possibili una replica primaria e 4 repliche secondarie sincrone.
Inoltre, è stato introdotto il reindirizzamento della connessione di replica da secondaria a primaria, consentendo di orientare le connessioni dell'applicazione client alla replica primaria, indipendentemente dal server di destinazione specificato nella stringa di connessione. Questa funzionalità consente il reindirizzamento della connessione senza un listener.
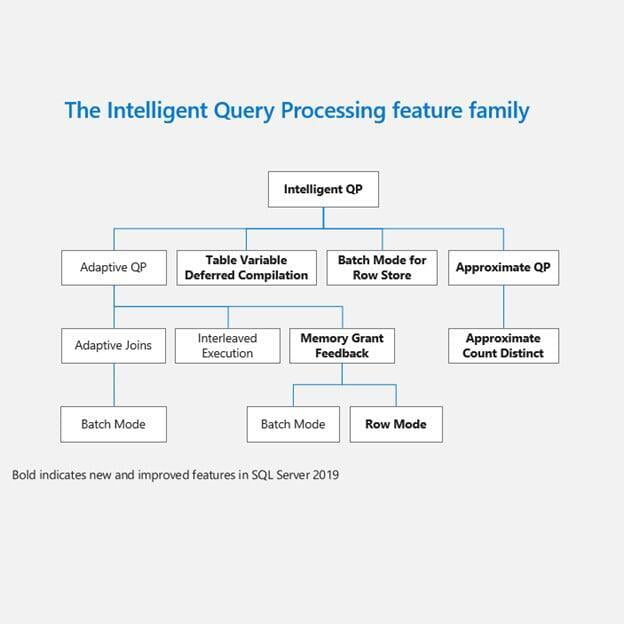
Elaborazione di query intelligenti
Il nuovo sistema di elaborazione di query intelligenti è un meccanismo volto a correggere i comuni problemi di performance di certe query, prendendo dei correttivi automatici durante il runtime delle stesse (si basa sulla raccolta statistica delle passate esecuzioni). Microsoft sta già utilizzando tale funzionalità su Azure SQL e viene ora reso disponibile anche su SQL Server 2019.
Supporto esteso per i dispositivi con memoria persistente
Qualsiasi file SQL Server inserito in un dispositivo con memoria persistente può ora essere eseguito in modalità con riconoscimento. SQL Server accede direttamente al dispositivo, ignorando lo stack di archiviazione del sistema operativo e usando operazioni I/O efficienti. Questa modalità migliora le prestazioni poiché consente input/output a bassa latenza su tali dispositivi.
UTF-8 support
L’utilizzo della diffusa codifica UTF-8 permette un notevole risparmio di spazio nella memorizzazione dei campi di testo, permettendo una compressione dei caratteri già esistenti senza bisogno di routine addizionali. Si può arrivare ad un risparmio del 50% nella memorizzazione dei caratteri. La codifica UTF-8 è consentita nei tipi di dati CHAR e VARCHAR.
Big Data Cluster
L’ultima versione di SQL Server 2019 semplifica notevolmente la Big Data Analytics per gli utenti finali. Con la funzionalità Big Data Cluster di SQL Server è possibile distribuire cluster scalabili di containers di SQL Server, Spark e HDFS in esecuzione in Kubernetes. Questi componenti sono in esecuzione side-by-side per consentire la lettura, scrittura ed elaborazione di big data da Transact-SQL o Spark, consentendo con facilità di combinare e analizzare i dati relazionali di valore elevato e con volumi elevati.
Machine Learning e intelligenza artificiale integrata
I cluster di big data di SQL Server consentono efficienti attività sui dati archiviati nel pool di archiviazione HDFS. È possibile usare Spark e gli strumenti di intelligenza artificiale e machine learning incorporati in SQL Server con integrazione di linguaggi come R, Python, Scala o Java.
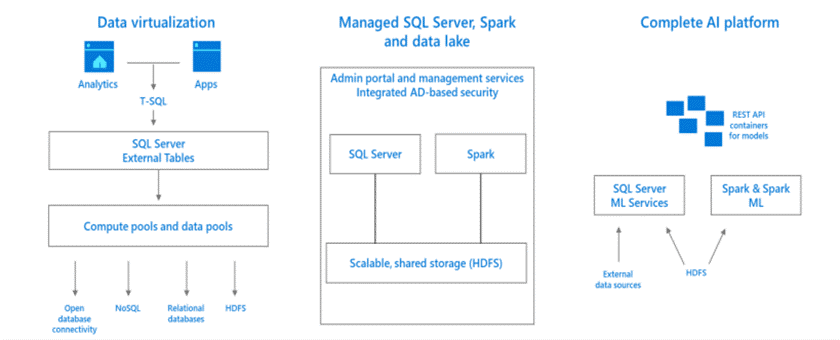
Virtualizzazione dei dati
Una delle funzionalità chiave per SQL Server 2019 è la possibilità di virtualizzare i dati. Questo processo consente di mantenere i dati nella posizione originale. È possibile virtualizzare i dati in un'istanza di SQL Server in modo da poter eseguire query nella versione virtualizzata come in qualsiasi altra tabella in SQL Server. In questo modo si riduce al minimo la necessità di ricorrere a processi ETL (estrazione, trasformazione e caricamento). Per eseguire il processo è necessario l'uso di connettori Polybase, che permettono l’integrazione di dati con differenti sorgenti, quali MongoDB, Oracle, DB2, Cosmos, and Hadoop Distributed File System (HDFS).
Creazione di indici online ripristinabili
Con la creazione di indici online ripristinabili, un'operazione di creazione indice può essere sospesa e ripresa in seguito dal punto in cui è stata interrotta, anziché riavviarla dall'inizio.
La creazione di indici online ripristinabili supporta gli scenari seguenti:
- Ripristino di un'operazione di creazione indice dopo un errore di creazione indice, ad esempio in seguito a un failover del database o all'esaurimento dello spazio su disco.
- Sospensione temporanea di un'operazione di creazione indice e ripresa in un secondo momento, per consentire di liberare temporaneamente risorse di sistema in base alle esigenze e quindi riprendere l'esecuzione.
- Creazione di indici di grandi dimensioni senza usare grandi quantità spazio di registro, senza un'esecuzione prolungata che blocca altre attività di manutenzione e con la possibilità di troncare il log.
In caso di un errore di creazione indice, senza questa funzionalità la creazione indice online va eseguita di nuovo e l'operazione deve essere riavviata dall'inizio.
Individuazione e classificazione dei dati
Si tratta di una funzionalità avanzata di individuazione e classificazione dei dati incorporata a livello nativo in SQL Server. La classificazione e l'assegnazione di etichette ai dati più sensibili offre diversi vantaggi:
- Contribuisce a soddisfare i requisiti in materia di privacy e di conformità alle normative.
- Supporta scenari di sicurezza, quali il monitoraggio (controllo) e gli avvisi in caso di accesso anomalo ai dati sensibili.
- Semplifica l'identificazione della posizione dei dati sensibili nell'organizzazione, in modo che gli amministratori possano adottare le misure necessarie per la protezione del database.
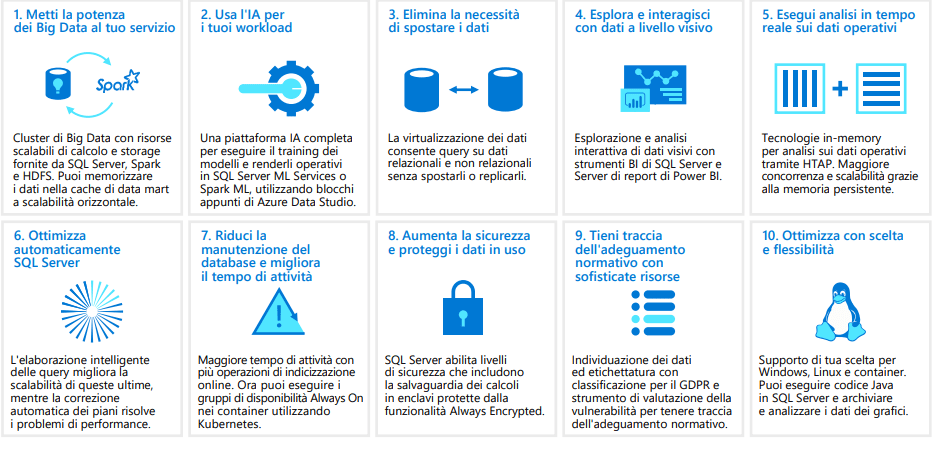
SQL Server 2019 introduce quindi numerose nuove funzionalità, con attenzione particolare per le performance, la sicurezza, l’affidabilità, la produttività degli sviluppatori.
Microsoft SQL Server 2019 è disponibile dal 5 novembre, data della presentazione ufficiale a Microsoft Ignite 2019.
di Matteo Dal Bianco, pubblicato il 23 ottobre 2019