Le operazioni di PIVOT e UNPIVOT son ben note a chiunque debba lavorare con strumenti quali Excel. In SQL Server, questi due operatori relazionali possono essere utilizzati per modificare un’espressione con valori di tabella in un’altra tabella. Essi consentono rispettivamente di trasformare valori di una tabella in valori di colonne e, viceversa, valori di colonna in valori di tabella. Vediamo come usarli.
PIVOT
Questa operazione trasforma i valori di una tabella in colonne della tabella stessa. Vediamo degli esempi.
Poniamo di avere una tabella anagrafica dei prodotti di questo tipo:
CREATE TABLE Prodotto ( [CodProdotto] VARCHAR(10) ,[Categoria] VARCHAR(100) ,[Anno] NUMERIC(4, 0) ,[Prezzo] NUMERIC(11, 2) )
In ogni record abbiamo il codice del prodotto, la sua categoria, la sua marca ed il prezzo. Poniamo di avere i seguenti dati in tabella:
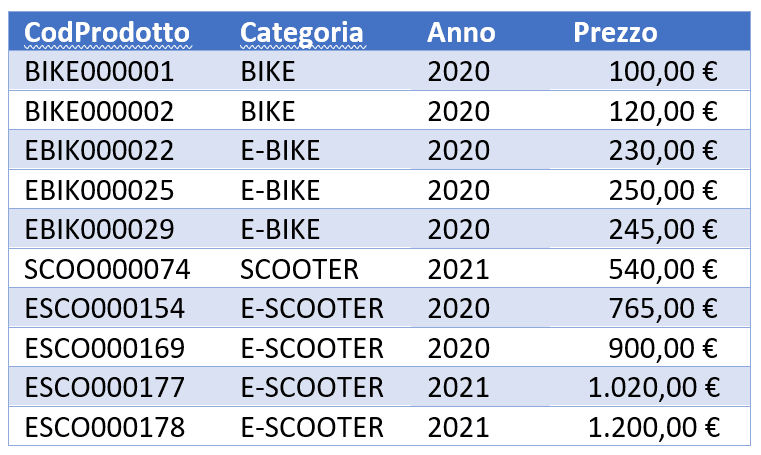
Vogliamo calcolare il prezzo medio per categoria, ma avendo le categorie come intestazioni di colonna di una nuova tabella. Il risultato dovrà quindi risultare in un unico record, come segue:

SELECT * FROM ( SELECT [Categoria] ,[Prezzo] FROM [dbo].[Prodotti] ) T PIVOT( AVG([Prezzo]) FOR [Categoria] IN ( [BIKE] , [E-BIKE] , [SCOOTER] , [E-SCOOTER] )) AS PivotTable;
Ogni colonna addizionale che si aggiungerà alla lista di selezione (clausola SELECT) della query che ritorna il dataset di base per il pivoting (subquery T), formerà automaticamente dei raggruppamenti nella tabella finale risultante. Per esempio:
SELECT * FROM ( SELECT [Categoria] ,[Anno] ,[Prezzo] -- N.B. è stato aggiunto l’anno FROM [dbo].[Prodotti] ) T PIVOT( AVG([Prezzo]) FOR [Categoria] IN ( [BIKE] , [E-BIKE] , [SCOOTER] , [E-SCOOTER] )) AS PivotTable;
dà come risultato il seguente dataset:

UNPIVOT
Essa trasforma le colonne di una tabella in valori della tabella stessa. Vediamone degli esempi.
Poniamo di avere una tabella delle vendite d’abbigliamento di questo tipo:
CREATE TABLE Vendite ( [NrOrdine] VARCHAR(6) ,[CodArticolo] VARCHAR(10) ,[QtaXXS] INT ,[QtaXs] INT ,[QtaS] INT ,[QtaM] INT ,[QtaL] INT ,[QtaXL] INT ,[QtaXXL] INT )
In ogni record abbiamo il numero dell’ordine di vendita, il codice dell’articolo che vendiamo, e sette colonne ciascuna indicante la quantità di articolo venduti per ciascuna taglia, dalla XXS alla XXL. Per semplicità di esempio, prendiamo un solo record da questa tabella:

Vogliamo trasformare questo singolo record in una tabella siffatta:
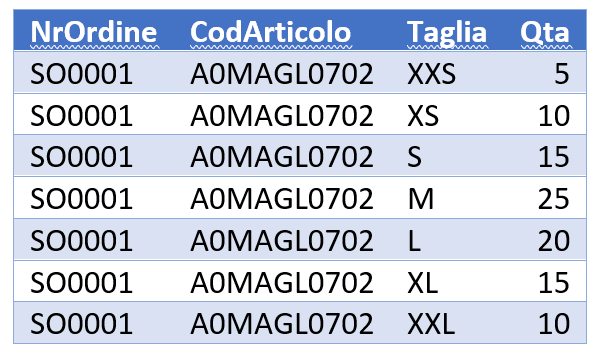
In altre parole, vogliamo che le sette colonne divengano dei valori di tabella, generando sette record – uno per ciascuna delle sette taglie – a partire dall’unico che abbia preso in considerazione. Per far ciò, eseguiremo un’operazione di UNPIVOT, scrivendo la seguente query:
SELECT U.[NrOrdine] ,U.[CodArticolo] ,RTRIM(SUBSTRING(U.[Taglia], 4, 3)) AS [Taglia] ,U.[Qta] FROM [dbo].[Vendite] V UNPIVOT([Qta] FOR [Taglia] IN ( [QtaXXS] ,[QtaXS] ,[QtaS] ,[QtaM] ,[QtaL] ,[QtaXL] ,[QtaXXL] )) U;
NB. Senza l’operazione di SUBSTRING, il valore stringa della nuova colonna [Taglia]comprenderebbe anche il Qtainiziale.
Questo esempio è particolarmente semplice dato che le colonne delle quantità hanno tutte lo stesso tipo di dato, ovvero int. Se avessimo invece colonne di tipo diverso, anche solo nella lunghezza (per le stringhe) o precisione e scala (per i decimali)? In questo caso, è sufficiente dapprima convertire tutte le colonne interessate dall’operazione di UNPIVOT. Risulta di estrema comodità l’utilizzo di una common table expression: vediamo col seguente esempio, dove abbiamo delle colonne di tipo stringa, che poniamo essere tutte di differente lunghezza per definizione, e che decidiamo di convertire in nvarchar(MAX).
WITH CTE_AnagCli AS ( SELECT [CodCliente] ,CAST([CodFiscale] AS NVARCHAR(MAX)) AS [CodFiscale] ,CAST([PartitaIva] AS NVARCHAR(MAX)) AS [PartitaIva] ,CAST([Indirizzo] AS NVARCHAR(MAX)) AS [Indirizzo] ,CAST([Località] AS NVARCHAR(MAX)) AS [Località] ,CAST([CAP] AS NVARCHAR(MAX)) AS [CAP] ,CAST([Comune] AS NVARCHAR(MAX)) AS [Comune] ,CAST([Provincia] AS NVARCHAR(MAX)) AS [Provincia] FROM [dbo].[AnagraficaCliente] ) SELECT U.[CodCliente] ,U.[Campo] ,U.[Valore] FROM CTE_AnagCli S UNPIVOT([Valore] FOR [Campo] IN ( [CodFiscale] ,[PartitaIva] ,[Indirizzo] ,[Località] ,[CAP] ,[Comune] ,[Provincia] )) U WHERE 1 = 1 AND U.[Valore] <> '' -- Rimuovo i record dove manca l’informazione ;
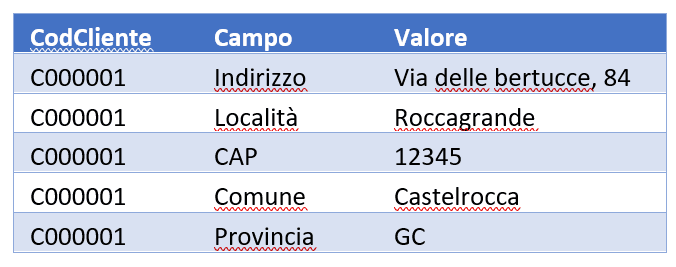
In questo modo, trasformeremo il primo record (dove CodFiscale e PartitaIvasono valorizzate a stringa vuota)

nella tabella sottostante:
Conclusioni su PIVOT e UNPIVOT in SQL Server
Come abbiamo visto, lo scopo dell’operatore PIVOT è trasformare i valori univoci sulle righe di una colonna in vere e proprie colonne con aggregazione dei risultati; UNPIVOT ruota le colonne in righe, ovvero trasforma i valori di colonna in valori della tabella, posizionandoli su più righe.
Queste trasformazioni sono di estrema utilità in differenti scenari: non solo per l’analisi dei dati, ma anche in contesti di Business Intelligence quali la realizzazione di un report od una dashboard, oppure nelle fasi di trasformazione dei dati in ETL (o, più in generale, nella Data Integration).
E se non conoscessimo gli oggetti su cui fare PIVOT?
Dal primo esempio affrontato, appare chiaro come sia necessario conoscere in anticipo i valori che la colonna [Categoria] può assumere, ovvero i valori di colonna sulla quale eseguire il pivoting. Ma se non conoscessimo a priori questo elenco? Come potremmo scrivere un comando SQL che sia autonomo nella scrittura degli oggetti di pivoting?
In questo caso, è necessario procedere con la scrittura di codice SQL dinamico. Ciò significa implementare una procedura che dapprima componga il testo del comando SQL in accordo alla lista di valori contenuti nella colonna di riferimento, e che poi esegua tale codice. Vediamo come fare.
Se il nostro obiettivo è un PIVOT dinamico, la procedura vedrà un codice come quello che segue:
-- Variabile stringa che conterrà l’elenco dei valori che diverranno colonne
-- I nomi delle colonne sono fra parentesi quadre, e separati da una virgola
DECLARE @columns AS NVARCHAR(MAX) = '';
-- Valorizzazione della variabile
SELECT @columns = @columns + QUOTENAME([Categoria]) + ', '
FROM (
SELECT DISTINCT [Categoria]
FROM [dbo].[Prodotti]
) Q;
-- Rimozione della virgola finale
SELECT @columns = SUBSTRING(@columns, 0, LEN(@columns));
-- Variabile stringa che conterrà il testo del comando SQL 'SELECT ... PIVOT ...'
DECLARE @queySelect AS NVARCHAR(MAX) = '';
-- Generazione dinamica del comando SQL
SET @queySelect = N'SELECT * FROM
(
SELECT [Categoria], [Prezzo]
FROM [dbo].[Prodotti]
) T
PIVOT
(
AVG( [Prezzo] )
FOR [Categoria] IN ( ' + @columns + '
) AS PivotTable';
-- Esecuzione del comando SELECT
EXEC sp_executesql @queySelect;;
L’esecuzione della variabile @querySelect restituirà il codice SQL del comando SELECT da lanciare per il pivoting desiderato.
di Thomas Tolio, aggiornato il 1 febbraio 2023
Hai bisogno di aiuto con SQL Server?
Non aspettare che i problemi si accumulino: siamo qui per aiutarti. Che si tratti di ottimizzare i tuoi database, risolvere un rallentamento o costruire una strategia su misura, la soluzione inizia con una chiacchierata.
Contattaci oggi stesso: rispondiamo in fretta e parliamo la tua lingua, senza complicazioni.