L’articolo odierno vuole porre il focus sulla stored procedure di Ola Hallegren, IndexOptimize, per la manutenzione degli indici e delle statistiche in SQL Server. Nello specifico si vuole mostrare come lo strumento con un minimo di studio ci permette di superare ampiamente e brillantemente i limiti del Maintenance Plan standard di Microsoft.
Quando si parla di manutenzione indici si affronta una tematica largamente trattata in letteratura e fa parte dell’abc delle attività di una DBA Microsoft SQL Server. Spesso, inoltre, anche una figura che non è propriamente un DBA conosce i rudimenti della tematica o se ne interessa per diverse ragioni, sia egli un amministratore di sistema o un programmatore.
La frammentazione di un indice è sinonimo di degradazione delle prestazioni delle query (soprattutto so grandi tabelle) è quindi doveroso e lungimirante creare dei piani di manutenzione a supporto dell’attività per supervisionare e ridurre la problematica.
Microsoft Maintenance Plan
Microsoft offre diversi approcci per gestire la manutenzione indici. Il più diffuso tra le soluzioni interne a Microsoft sicuramente è il “Maintenance Plan” o Piano di Manutenzione.
Questa soluzione offre la possibilità di creare veri e propri workflow, componendo passo per passo le operazioni che vogliamo far eseguire a SQL; il tutto con un’interfaccia grafica piuttosto comoda che permette anche a utenti base e intermedi di raggiungere l’obiettivo senza troppe complicazioni. Con pochi click il piano e parti di esso sono poi facilmente schedulabili sull’Agent.
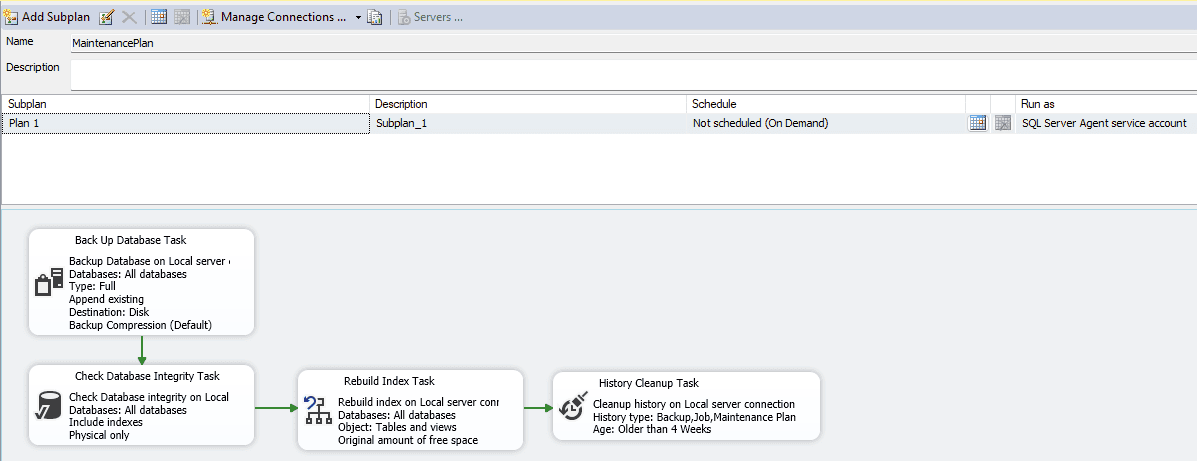
Per la manutenzione degli indici, nello specifico, le possibilità offerte sono due:
- Rebuild Index Task: per la ricostruzione indici.
- Reorganize Index Task: per la riorganizzazione.
All’interno dei due blocchi è poi possibile personalizzare il task specificando:
- La connessione e quindi su quale istanza eseguire l’operazione.
- Su quali database eseguire il task.
- Gli oggetti specifici da includere se nel punto precedente è stato selezionato un solo database.
Nella parte bassa della maschera sicuramente i punti salienti per entrambi i casi sono le soglie di elaborazione:
- “Fragmentation >”: ovvero considerare solamente indici con una frammentazione superiore ad una certa soglia.
- “Page Count >”: ovvero considerare solamente indici con un certo numero di pagine (per semplificare si immagini la dimensione in termine di record dell’indice).
- “Used in last”: ovvero considerare solamente indici che sono stati utilizzati recentemente in base alla soglia.
IndexOptimize
Con una singola stored procedure installata sull’istanza, IdexOptimize permette di raggiungere e superare il livello di parametrizzazione offerto dai task del maintenance plan.
Le caratteristiche principali sono:
- Facile da installare e alta portabilità.
- Alto livello di parametrizzazione.
- Possibilità di combinare assieme in un unico comando Rebuild e Reorganize.
- La gran parte dei parametri è già di default impostata su valori ampiamente accettati dalla community SQL Server validi per le installazioni più comuni.
Lo strumento non è supportato da interfaccia grafica ma lo scopo di questo articolo è proprio quello di evidenziarne potenzialità e semplicità di utilizzo una volta superato passato lo scoglio inziale.
Installare IndexOptimize
IndexOptimize, come detto, è una stored procedure, è facilmente scaricabile dal sito https://ola.hallengren.com/downloads.html come parte di una suite di comandi o singolarmente sotto forma di script di creazione sql.
Basta l’esecuzione dello script per installarla sull’istanza bersaglio.
Può essere creata in qualsiasi database a necessità, tipicamente sul database master.
Come si utilizza IndexOptimize
Per lanciare una ricostruzione indici basta quindi eseguire la stored procedure precedentemente installata, il parametro minimo da fornire è quali database presenti sull’istanza si vuole vengano inclusi con il parametro “@Databases”.
EXEC [master].dbo.IndexOptimize @Databases = 'ALL_DATABASES'
Utilizzando la parola chiave “ALL_DATABASES” si specifica alla procedura di includere tutti i database presenti in istanza. A partire dalla lista dei database andrà ad analizzare gli indici presenti e procederà alla manutenzione se compresi nei parametri operativi.
Anche senza ulteriore parametrizzazione la procedura andrà a eseguire una rebuild/reorganize con dei range operativi largamente approvati dalla community SQL Server e da Microsoft, il valore aggiunto si ottiene però comprendendone le potenzialità avanzate.
IndexOptimize, parametri operativi
Analizziamo adesso i parametri operativi a mio avviso più interessanti, per l’elenco ufficiale rimandiamo alla pagina ufficiale.
@Databases: permette di fornire la lista dei database da considerare nell’elaborazione ognuno separato da virgola “,”.
Fanno parte della lista delle parole riservate:
- ALL_DATABASES: tutti i database.
- SYSTEM_DATABASES: tutti i database di sistema.
- USER_DATABASES: tutti i database definiti dagli utenti.
- AVAILABILITY_GROUP_DATABASES: tutti i database presenti in Availability Group.
La lista può essere personalizzata ulteriormente con i l’utilizzo di:
- “ - “: per indicare di escludere un certo database.
- “%”: come caratteri jolly per le ricerche con wildcard
Esempio:
EXEC [master].dbo.IndexOptimize @Databases = “SYSTEM_DATABASES ,Advent % ,- AdventureWorks2019”
Tutti i database di sistema, più tutti i database che iniziano per “Advent” escluso “AdventureWorks2019”.
@FragmentationLow, @FragmentationMedium, @FragmentationHigh: questi tre parametri permettono di definire le azioni da eseguire per ciascuna soglia di frammentazione (vedi @FragmentationLevel):
- @FragmentationLow: comandi da eseguire in presenza di soglia bassa inferiore al primo valore di soglia (tipicamente nessuna operazione).
- @FragmentationMedium: comandi da eseguire in presenza di soglia media maggiore al primo valore di soglia ma inferiore al secondo (tipicamente reorganize).
- @FragmentationHigh: comandi da eseguire in presenza di soglia alta maggiore al secondo valore (tipicamente rebuild).
Per tutti e tre i parametri i valori possibili sono multipli e possono essere elencati separati con virgola, l’ordine indica con quale priorità la procedura tenta di applicarli.
I valori possibili sono:
- INDEX_REBUILD_ONLINE: ricostruzione online (se supportata) dell’indice.
- INDEX_REBUILD_OFFLINE: ricostruzione offline dell’indice.
- INDEX_REORGANIZE: riorganizzazione dell’indice.
- NULL: nessuna azione.
@FragmentationLevel1, @FragmentationLevel2: questi due parametri permetto di dichiarare due soglie in percentuale su cui definire quali attività eseguire per ogni soglia:
- FragmentationLevel1: percentuale di frammentazione per cui un valore maggiore o uguale è considerato del tipo @FragmentationMedium.
- FragmentationLevel2: percentuale di frammentazione per cui un valore maggiore o uguale è considerato del tipo @FragmentationHigh.
I valori di default sono rispettivamente 5 e 30%.
I 5 parametri lavorano assieme per definire soglie e tipologia di attività da eseguire. Schematizzando la cosa la possiamo immaginare così:

Con un solo comando è possibile definire una scaletta di attività in base alle soglie e con il valore aggiunto di poter eseguire comandi rebuild e reorganize con la stessa schedulazione!
Esempio:
EXEC [master].dbo.IndexOptimize @Databases = “ALL_DATABASES” ,@FragmentationLow = NULL ,@FragmentationMedium = 'INDEX_REORGANIZE' ,@FragmentationHigh = 'INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE' ,@FragmentationLevel1 = 30 ,@FragmentationLevel2 = 70
Eseguire il commando per tutti i database;
- per tutti gli indici frammentati sotto il 30% (@FragmentationLevel1 = 30) non eseguire nessuna attività (@FragmentationLow = NULL);
- per tutti quelli compresi tra 30 e 70 (@FragmentationLevel1 = 30, @FragmentationLevel2 = 70) esegui se una riorganizzazione (@FragmentationMedium = 'INDEX_REORGANIZE');
- per quelli superiore una rebuild online se possibile altrimenti offline (@FragmentationHigh = 'INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE').
@MinNumberOfPages, @MaxNumberOfPages: rappresentano le soglie per cui il comando ignora l’indice entro le soglie definite:
- MinNumberOfPages: indici con meno pagine del valore impostato, di default 1000 come da suggerimenti Microsoft.
- MaxNumberOfPages: indici con più pagine del valore impostato, di default non è impostata soglia.
Esempio:
EXEC [master].dbo.IndexOptimize @Databases = “ALL_DATABASES” ,@MinNumberOfPages = 500 ,@MaxNumberOfPages = 500000
Esegui la manutenzione di tutti gli indici di tutti i database con minimo 500 pagine e meno di 500000.
@SortInTempdb: indica se le operazioni ordinamento durante la manutenzione sono da eseguire nei datafiles del tempdb o all’interno del database stesso. Va valutato in base ai limiti presenti a livello datafiles e tempdb, la domanda da porsi è: preferisco che “cresca” più il tempdb o i files dei singoli database causa manutenzione? Il valore di default è “N” (No) quindi i files interessanti sono quelli del singolo database.
@Indexes: con questo parametro possiamo definire la lista specifica degli indici da manutenere, ognuno separato da virgola. Come avviene anche per @Databases è possibile combinare i caratteri “-” e “%” per personalizzare la lista nel dettaglio. La parola riservata “ALL_INDEXES” indica l’elaborazione dell’intera lista degli indici inclusi nelle soglie definite.
Vale la pena approfondire come utilizzare i caratteri speciali:
- anteporre “-” ad un oggetto in lista indica esclusione mentre
- “%” va approfondito va contestualizzato alla posizione in cui si inserisce
Per utilizzare la ricerca con wildcard va tenuto presente la gerarchia degli oggetti che lo script include ed è la seguente:
<<database>>.<<schema>>.<<tabella>>.<<indici>>
Per rendere più intuibile il concetto vediamo degli esempi.
Esempio1:
Voglio includere tutti gli indici dei database AdventureWorks2019 e AdventureWorks2022, ma del primo solamente dello schema “Person“ mentre del secondo lo schema “Production”:
@Indexes = “AdventureWorks2019.Person.%, AdventureWorks2022.Production.%”
NB: è possibile omettere la wildcard per gli indici (la parte <<indici>> a destra dell’ultimo punto) ) se non necessaria.
Esempio2:
Voglio includere tutti gli indici di tutti i database salvo le tabelle “ErrorLog” di tutti i database che iniziano per “Advent”:
@Indexes = “ALL_INDEXES, -Advent%.%.ErrorLog”
Se lo schema rimane sempre lo stesso per tutte le tabelle (tipicamente dbo) è possibile specificarlo in maniera esplicita senza wildcard:
@Indexes = “ALL_INDEXES, -Advent%.dbo.ErrorLog”
Esempio3:
Voglio includere tutti gli indici di tutti i database salvo per tutte le tabelle che iniziano per “Storico” l’indice “Idx_Storico_OLD”:
@Indexes = “ALL_INDEXES, -%.%.Storico%.Idx_Storico_OLD”
@TimeLimit: parametro che permette di impostare un valore espresso in secondi oltre cui la stored procedure non deve eseguire ulteriori comandi. Va tenuto presente che time limit non tronca nessun comando a metà al passare del tempo impostato, per cui se il comando fosse particolarmente “pesante” potrebbe proseguire oltre. In media però è un buon compromesso per assicurarsi una procedura più governabile evitando il più possibile sovrapposizioni con altre procedure.
Di default non c’è un tempo limite.
@Delay: permette di impostare un valore in secondi da far passare tra un comando e l’altro. Di default nessun delay.
@LockTimeOut: permette di impostare i secondi per cui ogni comando attende di poter mettere un lock per eseguire l’attività.
@LockMessageSeverity: permette di indicare come gestire eventuali time out, impostando il valore 10 avremmo un messaggio informativo, con 16 un vero e proprio errore. Il parametro è particolarmente utile in modalità soppressione dell’errore quando per casi noti sì vuole evitare lo spam di errori (es. invio mai la fronte di casi noti).
@LogToTable: parametro che permette di far sì che la procedura per ogni singolo indice accodi una riga nella tabella di log con i risultati del comando stesso. La tabella di log viene creata nel database master “dbo.CommandLog”.
I valori possibili sono “Y” (Si) o “N” (No), default “N”.
La tabella ha il valore aggiunto di poter essere usata come storico ed è facile costruire delle query di analisi tempi e trend.

@Execute: permette di specificare se la procedura deve essere eseguita. I valori possibili sono “Y” (Si) o “N” (No), default “Y”.
Potrebbe essere considerato superfluo ma tenendo conto che vengono comunque analizzati tutti gli indici dentro i parametri operativi definiti utilizzata con @LogToTable = “Y” ha anche la funzione di raccolta dati e test per calcolare la quantità di indici che verrebbero inclusi nell’elaborazione.
Update statistics
Per non appesantire troppo l’articolo odierno si è menzionato ma NON si approfondisce la parametrizzazione inerente all’aggiornamento delle statistiche, sarà trattato sicuramente più avanti con un focus solo sulla tematica.
Un esempio pratico di utilizzo
Possiamo immaginare una casistica di un’azienda produttiva con diversi applicativi per la gestione delle attività quotidiane ed un software documentale.
Per semplicità:
- MAG: database di gestione del magazzino
- GEST: database gestionale e amministrativo
- DOC: database documentale
La natura dei flussi impongono che durante la notte vengano manutenuti gli indici delle tabelle operative vitali inerenti le attività di magazzino ogni giorno mentre nel weekend con le attività principali ferme è possibile eseguire con più “calma” le manutenzioni più approfondite. Si hanno indicazioni inoltre per cui è possibile saltare tutta la parte di storico e log dei database.
Ipotesi di comando con schedulazione giornaliera:
EXEC [master].dbo.IndexOptimize @Databases = “MAG” ,@FragmentationLow = NULL ,@FragmentationMedium = 'INDEX_REORGANIZE' ,@FragmentationHigh = 'INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE' ,@FragmentationLevel1 = 50 ,@FragmentationLevel2 = 80 ,@Indexes = “ALL_INDEXES” ,@MinNumberOfPages = 1000 ,@LockTimeout = 120 ,@LockMessageSeverity = 10 ,@Timelimit = 14400 ,@LogToTable = ‘Y’
Si esegue la manutenzione strettamente al database MAG, le soglie sono alte per limitarsi alle tabelle critiche con indici da almeno diecimila pagine, è risaputo che possono esserci dei flussi che bloccano alcune tabelle per cui l’attesa di lock è ottimistica a due minuti me è accettato che ce ne siano e non serve loggarli come errori. In fine viene dato un limite di quattro ore in modo che la procedura non sia ancora attiva alla ripresa delle attività, il log su tabella è sempre gradito per eventuali indagini.
Ipotesi di comando con schedulazione nel fine settimana (domenica):
EXEC [master].dbo.IndexOptimize @Databases = “ALL_DATABASES” ,@FragmentationLow = NULL ,@FragmentationMedium = 'INDEX_REORGANIZE' ,@FragmentationHigh = 'INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE' ,@FragmentationLevel1 = 5 ,@FragmentationLevel2 = 30 ,@Indexes = “ALL_INDEXES ,- DOC.log.% ,- DOC.%.% _Storico ,- GEST.%.STO_ % ” ,@LockTimeout = 30 ,@LockMessageSeverity = 16 ,@LogToTable = ‘Y’
Si esegue la manutenzione per tutti i database, le soglie sono diminuite in modo di includere molti più oggetti. Sono da considerare tutti gli indici esclusi tutti gli indici delle tabelle: del database DOC con schema “log”, delle tabelle che terminano per “_Storico” e tutti quelli delle tabelle del database GEST qualsiasi schema che iniziano per “STO_”.
Non dovrebbero esserci attività esclusive sui database per cui si irrigidiscono tempi di lock e severity dei messaggi per delle notifiche più incisive. Log su tabella sempre gradito!
Conclusione
Con questo articolo si è voluto far scoprire un’alternativa ai piani classici di manutenzione Microsoft. Con un minimo di conoscenza dei parametri accettati è possibile avere una forte personalizzazione dell’attività cucita al meglio alle necessità di ogni installazione.
di Riccardo Trattenero, pubblicato il 13 giugn0 2024
Fonti:
https://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html
Ti serve aiuto con SQL Server?
Prenota un incontro con i nostri DBA e scopri come possiamo aiutarti ad ottenere il massimo dalla tua infrastruttura dati.