Quando parliamo di database relazionali, ogni colonna all'interno di una tabella dovrebbe contenere un valore. In alcuni casi però, questo valore è sconosciuto. Se prendiamo ad esempio la nostra tabella dei clienti, potrei non conoscere il numero di telefono di uno di questi. Quando il “valore” da inserire all’interno di un campo è sconosciuto si definisce quindi un NULL.
Significato di NULL
La precedente non è l’unica interpretazione del NULL. Da quando sono nati i database relazionali negli anni settanta, sono state proposte 14 interpretazioni diverse. La gran parte degli autori converge però su due significati principali:
- Valore sconosciuto: un valore che esiste ma non è conosciuto.
- Valore non esistente: un valore che non esiste.
I puristi non considerano il NULL un valore ma una sorta di “marcatore”. Sostengono che se fosse un valore, dovrebbe comportarsi come tutti gli altri valori che possiamo assegnare ad un tipo dato all’interno del nostro database. Per questo motivo la specifica ANSI SQL-92 afferma che un NULL deve essere uguale per tutti i tipi di dati, in modo che tutti i NULL siano gestiti in modo coerente. Nel linguaggio corrente si sente comunque spesso parlare di valore NULL.
La logica cambia...
Codd, il padre della teoria relazionale, ha formalizzato il concetto di valore sconosciuto introducendo quella che è conosciuta come “logica a tre valori” nella quale, oltre ai valori VERO e FALSO, affianca il valore FORSE. E le cose si sono fatte interessanti…
Una semplice espressione come ad esempio X > Y o X = Y, seguendo i principi della logica tradizionale (Booleana) sarebbe valutata TRUE o FALSE se X che Y non sono valori nulli. Ma cosa succede se X o Y o entrambi fossero valori nulli? In questo caso l'espressione sarebbe valutata FORSE.
In AND, OR e NOT booleani, il comportamento dei valori NULL è specificato dalle seguenti tabelle di verità, dove T sta per True, U per Unknown (valore sconosciuto = NULL = FORSE) e F per falso.

Qualsiasi espressione aritmetica poi genera un NULL se un operando di tale espressione è esso stesso un valore NULL. Pertanto, nelle espressioni aritmetiche unarie (se A è un'espressione con un valore NULL), sia +A che !A (negazione) restituiscono NULL.
Nelle espressioni binarie, se uno (o entrambi) degli operandi A o B ha il valore NULL, A + B, A - B, A * B, A / B e A% B generano tutte un NULL (gli operandi A e B devono essere espressioni numeriche).
Se un'espressione contiene un'operazione relazionale e uno (o entrambi) gli operandi hanno il valore NULL, il risultato di questa operazione sarà NULL. Quindi, ciascuna delle espressioni A = B, A <> B, A <B e A> B restituirà anch'essa un NULL.
Cosa succede in SQL Server
SQL Server si comporta come tutti gli altri database relazionali. È essenziale prima rimarcare che un NULL non è uguale a 0 o a un valore blank. NULL significa che non è stata immessa alcuna voce per la colonna e implica che il valore è sconosciuto o non applicabile. Uno “zero” o uno spazio vuoto sono invece dei valori che vengono memorizzati all’interno del campo.
Quando creiamo una nuova tabella, possiamo decidere se un campo accoglierà o meno dei NULL.

Qualsiasi valore NULL nell'argomento delle funzioni aggregate AVG, SUM, MAX, MIN e COUNT viene eliminato prima che venga calcolata la rispettiva funzione (ad eccezione della funzione COUNT (*)). Se una colonna contiene solo valori NULL, la funzione restituisce NULL. La funzione aggregata COUNT (*) gestisce tutti i valori NULL allo stesso modo dei valori non NULL. Se la colonna contiene solo valori NULL, il risultato della funzione COUNT (nome_colonna DISTINCT) è 0.

SELECT COUNT(*) FROM dbo.Customer;--risultato: 4 SELECT COUNT(PhoneNumber) FROM dbo.Customer;--risultato: 2 SELECT SUM(Turnover) FROM dbo.Customer;--risultato: 2650
Poiché un valore null non è un valore, non è maggiore di, minore di o uguale a qualsiasi altro valore. E un null non equivale ad un altro null. Non è valido verificare se una colonna è = NULL, <NULL, <= NULL,> NULL o> = NULL. Questi sono tutti insignificanti perché null è l'assenza di un valore. Quindi cosa succede se si desidera trovare righe in cui una determinata colonna è nulla?
SELECT * FROM dbo.Customer WHERE Turnover = NULL --nessun record restituito SELECT * FROM dbo.Customer WHERE Turnover IS NULL --restituito CustomerID 002 SELECT * FROM dbo.Customer WHERE Turnover >= 800 --restituito CustomerID 001 e 003 SELECT * FROM dbo.Customer WHERE Turnover < 800 --restituito CustomerID 004
In SQL Server esiste l’opzione SET ANSI_NULLS che controlla il comportamento dell’operatore di uguaglianza (=) e di confronto (<>) nelle query durante la gestione dei record che contengono NULL. Il valore di default è ON che rappresenta anche lo standard ISO. Ma se imposto ad OFF questa opzione, la comparazione di qualsiasi valore nei confronti di un NULL sarà valutata TRUE.
SET ANSI_NULLS OFF SELECT * FROM dbo.Customer WHERE Turnover = NULL --restituito CustomerID 002
In SQL Server è ancora concesso l’utilizzo di questa opzione ma nelle prossime versioni di SQL questo comportamento sarà deprecato: SQL Server si comporterà solo come definito dallo standard ISO e l’utilizzo di SET ANSI_NULLS OFF genererà un errore.
Possiamo utilizzare alcune funzioni che ci aiutano nella gestione dei NULL:
- ISNULL, sostituisce NULL con un valore specificato. Nel nostro esempio, sostituiamo con uno zero eventuali Turnover nulli.
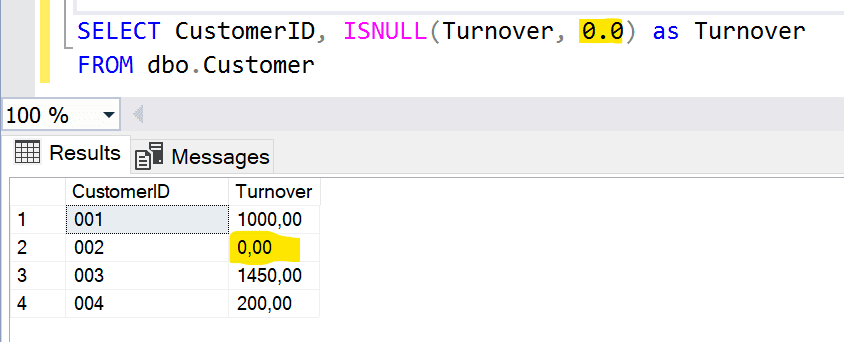
- COALESCE, ritorna il primo valore non NULL da una lista di valori. Ad esempio:
SELECT COALESCE(NULL, NULL, 3, 4) --restituisce il valore 3
Attenzione ad alcuni aspetti:
- ISNULL è una funzione proprietaria di SQL Server mentre COALESCE è una funzione definita nello standard ANSI. Ciò implica che per la portabilità è preferibile COALESCE.
- ISNULL accetta solo due argomenti mentre COALESCE può accettare più di due argomenti.
- Il tipo di dati del valore restituito da ISNULL è determinato dal tipo di dati del primo argomento, mentre il tipo di dati del valore restituito da COALESCE è determinato dal tipo di dati nell'elenco con la precedenza più alta.
- Quando entrambe le funzioni vengono utilizzate con le query secondarie, ISNULL offre prestazioni migliori poiché COALESCE viene tradotto internamente in un'espressione CASE.
Join e NULL
Quando ci sono valori nulli nelle colonne delle tabelle che vogliamo relazionare, i valori nulli non potranno essere confrontati (ricordate: NULL = NULL non restituisce TRUE).
I valori NULL in una colonna di una delle tabelle da unire può essere restituita solo utilizzando un join esterno (a meno che la clausola WHERE non escluda valori null).
Facciamo qualche esempio: utilizziamo la tabella Country che contiene questi valori (la tabella è stata costruita in questo modo solo a scopo dimostrativo).
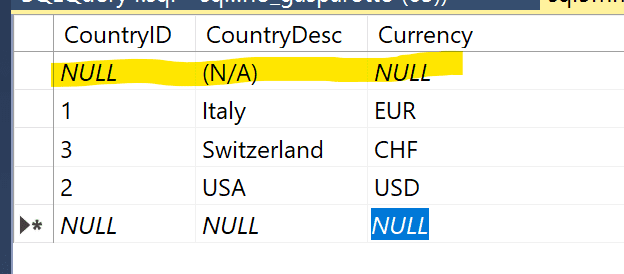
Se eseguiamo questa query:
SELECT [CustomerID] ,[CustomerName] ,[PhoneNumber] ,C.[CountryID] ,[Turnover] FROM [dbo].[Customer] C INNER JOIN [dbo].[Country] Y ON C.CountryID = Y.CountryID
Ci saranno restituiti questi record:

Come potete osservare, nonostante nella tabella Country sia presente un record con CountryID = NULL e Uno dei clienti abbia anch’esso CountryID = NULL, il join non è soddisfatto. Per restituire anche quel record dovremo utilizzare un LEFT JOIN.
Indici e NULL
SQL server tratta i NULL come dei valori quando ci riferiamo agli indici. Questo significa che se creo un un indice univoco o un costraint su una colonna che consente i NULL, potrò avere un solo record che contenga questo valore altrimenti riceverò un errore.
Altra considerazione da fare riguarda lo scenario in cui una colonna che consente NULL ha solo un numero limitato di valori rilevanti utilizzati nelle query. In questo caso è possibile creare un indice filtrato (filtered index) solo nel sottoinsieme di valori. Ad esempio, quando i valori in una colonna sono principalmente NULL e la query seleziona solo dai valori non NULL, è possibile creare un indice filtrato per le righe di dati non NULL. L'indice risultante sarà più piccolo e avrà un costo inferiore da mantenere rispetto a un indice non cluster creato sulla tabella completa e definito sulle stesse colonne chiave.
Conclusioni
In questo articolo, abbiamo discusso il concetto di NULL ed il suo legame con la logica a tre valori. Abbiamo descritto alcune particolarità legate a SQL Server ed alcune funzioni che ci aiutano a gestire set di dati contenenti NULL. Il tema è ancora ampio e molto si è scritto su questo argomento ma abbiamo voluto cercare di raccogliere le informazioni più rilevanti che ci possono servire nella nostra attività di sviluppo di basi di dati.Fonti:
- F. Codd, Relational Model for Database Management (1990)
- C.J. Date, SQL and Relational Theory: How to Write Accurate SQL Code (2009)
- SET ANSI_NULLS (Transact-SQL)
di Cristiano Gasparotto, pubblicato il 6 aprile 2020
Hai un dubbio o un problema? Parliamone!
Ogni grande progetto inizia con una chiacchierata.
Se vuoi migliorare le performance, risolvere un problema o semplicemente confrontarti, contattaci.