Un Database Administrator (DBA) deve spesso affrontare durante il suo lavoro quotidiano attività ripetitive, come ad esempio monitorare le prestazioni e lo stato del database server tramite viste diagnostiche e di sistema. Tutto ciò porta il DBA ad essere sempre a contatto con una grande mole di dati da gestire, spostare ed analizzare.
In questo articolo introduttivo vedremo come creare degli utility script in Python per interagire con SQL Server, interrogare ed analizzare viste diagnostiche, visualizzare graficamente i dati ottenuti e leggere i dati da un file Excel/csv e portarli dentro ad una tabella di un database.
Python
Python di per sé non ha bisogno di molte presentazioni, è uno dei linguaggi di programmazioni più utilizzati al mondo: è versatile e ha una sintassi molto facile da comprendere ed imparare. Uno dei suoi punti di forza è la capacità di interagire con grandi volumi di dati; infatti, grazie al suo ricco sistema di librerie, è possibile applicare calcoli matematici complessi e operazioni di pulizia/manipolazione. Inoltre è dotato di funzioni integrate per interagire con il file system.
Connettere Python con SQL Server
Per interagire con SQL Server useremo la libreria pyodbc: un'interfaccia per connettersi a SQL Server che utilizza i driver ODBC (Open Database Connectivity).
Per installare la libreria utilizziamo il gestore di pacchetti PIP.
pip install pyodbc
Ora vediamo come creare una stringa di connessione, eseguire un predicato T-SQL e visualizzare il risultato.
1. Per creare la stringa di connessione possiamo usare l’autenticazione di windows o un login SQL Server, poi dobbiamo passare parametri come nome dell’istanza, database, eventuale user e password.
Autenticazione Windows.
import pyodbc SERVER = "ServerName" DATABASE = "DatabaseName" conn = pyodbc.connect("DRIVER={SQL Server};" "SERVER=" + SERVER + ";" "PORT=1443;" "DATABASE=" + DATABASE + ";" "Trusted_Connection=yes;")
Autenticazione SQL Server.
SERVER = "ServerName" DATABASE = "DatabaseName" USERNAME = "usertdtmz" PASSWORD = "pwddtmz24!" conn = pyodbc.connect("DRIVER=SQL Server;
SERVER=" + SERVER + "; DATABASE=" + DATABASE + ";
UID=" + USERNAME + ";PWD=" + PASSWORD)
2. Una volta creata la stringa di connessione abbiamo bisogno di un oggetto chiamato cursore che ci permetterà di avere accesso all’istanza e poi eseguire una query.
cursore = conn.CURSOR ()
3. Creiamo la nostra query T-SQL da passare al cursore per poi eseguirla. Poi usiamo il metodo ‘fetchall’ del cursore per ottenere i record e poi visualizzarli con un for loop. Una volta ottenuti i risultati chiudiamo la connessione.
tsql = "SELECT * FROM nome_tabella" CURSOR. EXECUTE (tsql) TABLE = CURSOR.fetchall() FOR row IN table: PRINT (row) conn. CLOSE ()
Ora che abbiamo visto come creare una stringa di connessione ed interrogare il database passiamo a degli esempi pratici, che possono essere applicati durante il lavoro quotidiano di un DBA.
Esempio 1 – Automazione della lettura e analisi di viste diagnostiche
Tra le query più eseguite da un DBA figurano sicuramente le viste diagnostiche di SQL Server (Dynamic Management Views), che forniscono informazioni preziose sullo stato del database server.
In questo esempio, tra le molteplici possibilità, interroghiamo la vista diagnostica per il monitoraggio delle sessioni attive, sys.dm_exec_session.
Oltre a pyodbc, useremo pandas, una libreria di Python che permette di caricare dati in strutture dati tabellari chiamate DataFrame, eseguire operazioni di filtraggio, aggregazione e trasformazione
Di seguito lo script Python con i commenti che spiegano i passaggi.
import pyodbc import pandas AS pd SERVER = 'ServerName' DATABASE = 'DatabaseName' #Windows Auth conn = pyodbc.connect('DRIVER=SQL Server;SERVER=' + SERVER + ';PORT=1443;DATABASE=' + DATABASE + ';Trusted_Connection=YES') CURSOR = conn.CURSOR () # Query che interroga vista diagnostica per ottenere informazioni sulle sessioni # attive # il triplo apice serve a bypassare le stringenti regole di indentation di Python query = """
SELECT
session_id,
login_name,
status,
cpu_time,
memory_usage,
total_elapsed_time,
reads,
writes
FROM sys.dm_exec_sessions
WHERE status = 'running'
ORDER BY total_elapsed_time DESC
""" # Esecuzione della query e caricamento dei dati IN un DataFrame pandas df = pd.read_sql(query, conn) # Analisi dei dati(ad esempio, filtrare per richieste che durano più di 10 minuti) df_filtered = df [df[total_elapsed_time'] > 600000 ] #Visulizzazione dei dati IN formato tabellare
PRINT (df_filtered) # Chiusura della connessione conn.
CLOSE ()
Una volta eseguito lo script otterremo il seguente risultato in formato tabellare grazie alla dataframe di pandas.

Esempio 2 – Visualizzazione grafica dei dati
Come abbiamo visto, un DBA ha quotidianamente a che fare con grandi volumi di dati da analizzare. In questo, può essere aiutato dalla visualizzazione grafica, che costituisce uno dei punti di forza di Python.
Aggiungiamo a questo punto una terza libreria alla lista: matplotlib, che permette plottare i dati ottenuti su grafici.
Nell’esempio seguente creeremo uno script che genererà un grafico ad istogramma in cui mostra le principali 10 query per tempo totale e numero di esecuzioni: interrogheremo la vista sys.dm_exec_query_stats.
import pandas AS pd import pyodbc import matplotlib.pyplot AS plt SERVER = 'ServerName' DATABASE = 'DatabaseName' #Windows Auth conn = pyodbc.connect('DRIVER=SQL Server;SERVER=' + SERVER + ';PORT=1443;DATABASE=' + DATABASE + ';Trusted_Connection=YES') CURSOR = conn.CURSOR () # Query che interroga vista diagnostica per ottenere informazioni sulle statistiche delle query eseguite query = """
SELECT
sql_handle,
execution_count,
total_elapsed_time / 1000 AS total_elapsed_time_ms,
total_worker_time / 1000 AS total_worker_time_ms,
total_logical_reads,
total_physical_reads
FROM sys.dm_exec_query_stats
ORDER BY total_elapsed_time DESC
""" # Esecuzione della query e caricamento dei dati IN un DataFrame pandas df = pd.read_sql(query, conn) # Visualizzazione dei dati tramite funzioni e metodi di matplotlib df.head(10).plot(kind = 'bar', x = 'execution_count', y = 'total_elapsed_time_ms') plt.title('Top 10 query per tempo totale di esecuzione') plt.ylabel('Tempo totale di esecuzione (ms)') plt.xlabel('Numero di esecuzioni') plt.
show() # Chiusura della connessione conn.
CLOSE ()
L’output che otterremo è il seguente.
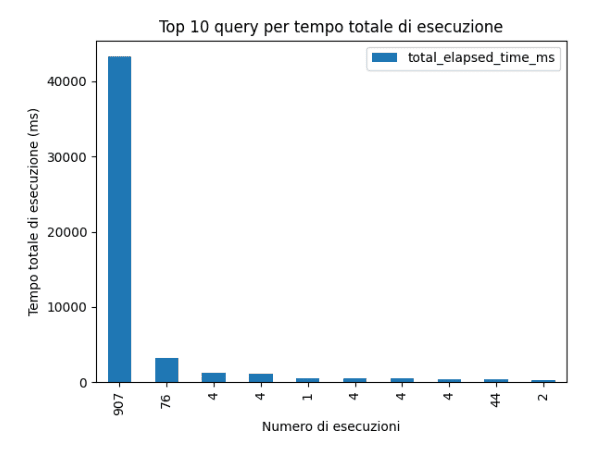
Esempio 3 – Caricamento dati su tabella SQL da file esterno
Un’altra operazione utile da semplificare è il caricamento dei dati da un file all'interno di una tabella SQL Server.
Nell’esempio seguente vedremo come caricare i dati da un file CSV.
Come primo passaggio creiamo un file CSV di prova, csvtoSQLpy.csv, con contenuto:
DepartmentID,Name,GroupName,
1,Engineering,Research and Development,
2,Tool Design,Research and Development,
3,Sales,Sales and Marketing,
4,Marketing,Sales and Marketing,
5,Purchasing,Inventory Management,
6,Research and Development,Research and Development,
7,Production,Manufacturing,
8,Production Control,Manufacturing,
9,Human Resources,Executive General and Administration,
10,Finance,Executive General and Administration
Sul database SQL creiamo la tabella dbo. DepartmentTestche ospiterà i nostri dati.
CREATE TABLE [dbo].[DepartmentTest] ( [DepartmentID] [smallint] NOT NULL ,[Name] [dbo].[Name] NOT NULL ,[GroupName] [dbo].[Name] NOT NULL )
Ora non ci resta che caricare i dati sulla tabella SQL con il seguente script Python. I vari passaggi sono spiegati nei commenti.
import pyodbc
import pandas as pd
# carichiamo i dati contenuti nel csv in un dataframe di panda
sdf = pd.read_csv(r'C:\Users\NabilElMerzouki\Documents\Datamaze\Tasks\perpy.csv')
# La stringa di connessione rimane sempre la stessa
SERVER = 'ODLW011'
DATABASE = 'AdventureWorks2019'
conn = pyodbc.connect('DRIVER= {SQL Server};SERVER='+SERVER+';PORT=1443;DATABASE='+DATABASE+';Trusted_Connection=YES')
cursor = conn.cursor()
# Inseriamo ogni riga contenuta del dataframe con un ciclo for
for index, row in df.iterrows():
cursor.execute("INSERT INTO dbo.DepartmentTest (DepartmentID,Name,GroupName) values(?,?,?)", row.DepartmentID, row.Name, row.GroupName)
conn.commit()
cursor.close()
conn.close()
Una volta eseguito lo script eseguiamo un SELECT per verificare che i dati siano stati caricati correttamente nella tabella.
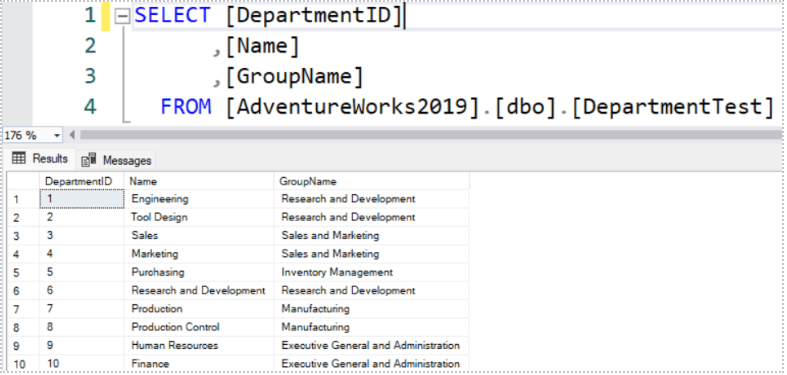
Conclusioni
Come abbiamo visto è molto semplice integrare dei predicati T-SQL all’interno di uno script Python. Questo apre moltissime possibilità per automatizzare le attività quotidiane di un DBA. Altre possibili applicazioni oltre a quelle analizzate in questo articolo sono creare dei meccanismi di backup automatici, monitorare lo spazio di archiviazione, analizzare le performance delle query e molto altro.
Insomma, molte delle attività ripetitive che un DBA esegue utilizzando comandi T-SQL possono essere automatizzate in uno script Python, ottimizzando così tempi e processi.
di Nabil El Merzouki, pubblicato il 29 agosto 2024