Cos'è il TempDB
Oggi scopriremo qualche dettaglio in più sul database di sistema più “amato” dai DBA SQL Server, il tempDB. Molto spesso non gli si da molta importanza, ma ci si accorge invece di quanto ne abbia, quando inizia a richiedere le nostre attenzioni.
Molto probabilmente avrai avuto già a che fare con i capricci del tempDB, in una maniera o nell’altra, ma in questo contesto vale comunque la pena rispolverare alcuni concetti basilari che lo riguardano.
Database di sitema
Cominciamo col dire che il tempDB è un database di sistema (quindi lo troveremo in qualunque installazione di SQL Server) ed è una risorsa “globale”, ossia qualunque utente collegato all’istanza, può utilizzarlo. Molto spesso l’utilizzo del tempDB è implicito, altre volte invece è l’utente stesso che crea degli oggetti che vanno a trovare posto nel tempDB.
Nel tempDB troviamo quindi i cosiddetti oggetti utente e oggetti interni, i primi riguardano gli oggetti creati in modo esplicito dall’utente, tra cui tabelle e indici temporanei globali o locali, stored procedures temporane, variabili di tabella, tabelle temporanee e cursori, mentre gli oggetti interni sono creati dallo stesso motore di SQL Server e sono riconducibili a tabelle in cui archiviare risultati intermedi di operazioni di spooling e di ordinamento cursori e LOB (Large Object) temporanei, risultati intermedi per hash join e aggregati, variabili XML, posta elettronica del database, oppure risultati intermedi ottenuti da creazione o ricompilazioni di indici (con l’opzione SORT_IN_TEMPDB)o per alcune query che contengono ORDER BY, GROUP BY, UNION, CHECKDB e notifiche eventi del Service Broker. Nel tempDB trovano posto anche Archivi di versioni, pagine di dati per il controllo della versione delle righe generate da operazioni come trigger, reindicizzazione online.
Macro-caratteristiche del tempDB
Le macro-caratteristiche del tempDB, sono:
- Il Recovery Model del tempDB è sempre in SIMPLE
- Il tempDB si ricrea ogni volta che SQL Server viene riavviato e la dimensione del datafiles e del T-log viene ripristinata come da preconfigurazione
- I dati presenti nel tempDB sono volatili
Al tempdb invece si applicano le seguenti restrizioni:
- Non è possibile creare filegroup
- Non si può effettuare il backup
- Non è possibile cambiare la collation, in quanto eredita quella di SQL Server
- Non si può modificare l’owner del Database
- Gli snapshot non sono ammessi
- Non si può eliminare
- Non è possibile eliminare l’utente guest del database
- Non può essere oggetto di mirroring
- Non è possibile rimuovere il filegroup primario del datafile prima o del t-log
- Non è ammesso ne DBCC CHECKALLOC ne DBCC CHECKCATALOG
- Non può essere portato offline
- Non è possibile impostare il filegroup primario o il database in READ_ONLY
Datafiles del tempDB
Dal punto di vista dei file il tempDB conta un numero di datafiles dipendente dal numero di processori logici presente nel server. Se il numero dei processori è <= 8, il tempDB deve avere un numero pari al numero dei processori logici; nel caso in cui il numero dei processori è >8, il numero dei datafiles è pari sempre a 8. Durante l’installazione è la wizard stessa che preconfigura il tempDB tenendo conto dei processori presenti in macchina. In alcuni casi potremmo trovarci di fronte a problemi di contesa e di conseguenza potrebbe risultare consigliabile aumentare il numero dei datafiles (per multipli di 4) fin quando la contesa si riduce a livelli accettabili, ma se questo non basta bisognerà rivedere il carico di lavoro o il codice.
Allocazione dello spazio per i datafiles
Per quanto riguarda l’allocazione dello spazio per i datafiles, Microsoft consiglia di fare in modo che il tempDB abbia una crescita automatica, ma in base alla mia esperienza ho sempre preferito allocare il tempdb assegnando il massimo spazio disponibile su disco. Personalmente uso questo metodo: dal totale disco tolgo il 15% ed il resto lo assegno in maniera uguale ai datafiles del tempDB; assegnare una dimensione identica ai datafiles permette a SQLServer di poter applicare la procedura di ottimizzazione del riempimento proporzionale per ridurre le contese. In ogni caso occorre ricordare che le dimensioni del tempdb deve essere ben ponderata, soprattutto se si sceglie di lasciare la crescita automatica, poiché se le dimensioni sono troppo ridotte, il carico di elaborazione del sistema potrebbe essere dovuto anche alla necessità di allargare automaticamente le dimensioni del tempDB fino a raggiungere quelle necessarie per il carico di lavoro. Nel caso in cui si scelga di utilizzare l’aumento automatico delle dimensioni, Microsoft consiglia di usare Database instant file initialization (se vuoi approfondire: https://learn.microsoft.com/en-us/sql/relational-databases/databases/database-instant-file-initialization?view=sql-server-ver16).
T-log
Per quanto riguarda invece il T-log, non impensierisce tanto quanto i datafiles poiché, essendo il tempDB in recovery model SIMPLE, registrerà il minimo delle transazioni, di conseguenza alloco solitamente dal 20% al 30% del totale dei datafiles.
Per verificare l’impostazione attuale del tempdb è possibile utilizzare la seguente query: 
Il tempDB dovrebbe essere sempre posizionato su dischi differenti da quelli dove vengono archiviati gli altri database.
Uno sguardo agli oggetti utente
Per archiviare temporaneamente i dati l’utente può utilizzare le tabelle temporanee locali, le tabelle temporanee globali o le variabili di tabella, ma non sarà possibile modificare la posizione in cui si trovano, poiché questo aspetto viene gestito in autonomia dal tempDB.
Una tabella temporanea locale viene definita assegnando il prefisso # ed è limitata alla sessione in cui è stata creata, ciò significa che nessuno, oltre a chi l’ha generata, può vederla e quando ci si disconnette oppure la sessione viene reimpostata, la tabella viene eliminata. Detto ciò, per creare una tabella temporanea basterà eseguire il comando seguente:

Le tabelle temporanee globali invece posso essere viste da tutte le sessioni connesse al server e sono definite con il prefisso ##

Una variabile di tabella invece, viene utilizzata in modo similare a quelle già viste con alcune differenze. La prima differenza sta nella dichiarazione della tabella, in quanto per poter creare una variabile di tabella occorre usare:

Oltre alla dichiarazione, una delle cose più importanti che contraddistingue questo oggetto temporaneo dalle altre due è che la variabile di tabella ha come ambito il batch e non la sessione.
Le differenze sostanziali tra tabelle temporanee e variabili di tabella posso essere riassunte come segue:
- Per le tabelle temporanee vengono create le statistiche, per le variabili di tabella no;
- Non è possibile creare indici nelle variabili di tabella ma è possibile creare vincoli. Ma ciò significa allo stesso tempo che creando chiavi primarie o vincoli univoci, si possono avere ugualmente indici.
- Le modifiche allo schema sono possibili nelle tabelle temporanee ma non sulle variabili di tabella.
- Nelle tabelle temporanee è consentito l’utilizzo di istruzione INSERT INTO … EXEC, nelle variabili di tabella no.
Uno sguardo agli oggetti interni
Come già detto, gli oggetti temporanei interni servono a SQL Server per archiviare momentaneamente i dati durante l’elaborazione delle query. Di conseguenza le operazioni di ordinamenti spool, hash join e cursori, hanno necessità di spazio sul tempDB per essere eseguite.
È possibile utilizzare la DMV sys.dm_db_session_space_usage per vedere quante pagine sono allocate per gli oggetti interni per ogni sessione, informazione disponibile nella colonna internal_object_alloc_page_count.
Uno sguardo all’archivio delle versioni (the version store)
L’archivio delle versioni viene utilizzato per archiviare le diverse versioni di righe di indici e dati e la funzionalità che lo utilizzano sono:
- Trigger
- Isolamento snapshot e isolamento snapshot Read-Commit (si tratta di due livelli di isolamento basati sul versionamento delle righe piuttosto che sul blocco)
- Operazioni sugli indici online: controllo delle versioni delle righe per supportare gli aggiornamenti dell’indice durante la ricostruzione
- MARS (Multiple Active Result Sets): controllo delle versioni delle righe per supportare l’interlacciamento di più richieste batch su una singola connessione.
Problemi comuni legati al tempDB
Attesa eccessiva per i Latch
E’ noto che i Latch vengono utilizzati per proteggere le pagine in memoria dalla modifica da parte di un’altra attività mentre il contenuto o la struttura vengono modificati o letti dal disco. Supponiamo adesso di creare (da un applicazione) una tabella temporanea, SQL Server, per determinare dove crearla, leggerà la pagina SGAM (mappa condivisa dell’allocazione globale) per trovare un’estensione mista con spazio libero da allocare per la tabella. SQL Server blocca con un latch esclusivo la pagina SGAM mentre aggiorna la pagina e poi passa a leggere la pagina PFS (spazio libero sulla pagina) per trovare una pagina libera all’interno dell’extent da allocare all’oggetto. SQL Server usa un latch esclusivo sulla pagina PFS per garantire che nessun altro processo possa allocare la stessa pagina dati, e rilascerà il latch ad aggiornamento concluso. Il processo descritto è un processo piuttosto semplice e funziona molto bene, fino a quando però il tempDB non è in uno stato di sovraccarico di richieste di allocazione ed iniziano a comparire attese PAGELATCH_UP. Per poter ridurre la probabilità di incorrere in questo tipo di problemi, ci sono delle operazioni proattive che possiamo fare.
Una prima opzione consiste nell’aumentare i datafiles del tempDB. Come abbiamo già visto è una buona pratica avere più datafiles poiché è possibile bilanciare il carico e quindi meno probabilità di incorrere in problemi di contese.
La seconda opzione è il riutilizzo temporaneo degli oggetti. Questa opzione si riferisce alla possibilità di SQL Server di memorizzare nella cache le definizioni temporanee degli oggetti in modo che possano essere riutilizzate. Questi oggetti quindi non dovendo essere ricreati, non richiederanno altro spazio, di conseguenza contribuiranno a risolvere i problemi di allocazione. SQL Server tenta di memorizzare le tabelle temporanee per impostazione predefinita, tuttavia conviene sapere che gli oggetti temporanei verranno memorizzati nella cache finchè:
- Non sono creati vincoli
- Le istruzioni come CREATE INDEX o CREATE STATISTICS non vengono eseguite dopo la creazione della tabella
- L’oggetto non viene creato tramite sp_executesql
- L’oggetto viene creato all’interno di un altro oggetto come:
- Stored procedures
- Trigger
- User-defined function
- La tabella restituita di una funzione con valori di tabella definita dall’utente.
Altro tipo di contesa è quella dei metadati, in pratica si tratta di una contesa sugli oggetti di sistema in tempdb che vengono utilizzati per tracciare le tabelle temporanee. Detto questo dobbiamo aggiungere che la cache non è una risorsa illimitata, di conseguenza occorre ripulirla per far spazio ad altri oggetti ed ogni volta che viene ripulita occorre eliminare anche le righe corrispondente dalle tabelle di metadati; si creano quindi contese sulle eliminazioni dalla cache. Microsoft è già intervenuta con delle ottimizzazioni che cito solo per conoscenza:
- E’ stato modificato il processo da sincrono ad asincrono
- Ridotto il numero di thread helper a uno per nodo NUMA e aumentato il numero di tabelle che vengono rimosse ad ogni passaggio
- È stato ottimizzata la strategia di latching utilizzata quando viene eseguita la scansione dei metadati
Nonostante ciò il problema non è stato completamente risolto, di conseguenza Microsoft consiglia:
- Non eliminare esplicitamente le tabelle temporanee alla fine di una stored procedure, poiché verranno ripulite al termine della sessione che le ha create
- Non modificare le tabelle temporanee dopo averle create
- Non troncare le tabelle temporanee
SQL Server 2019 introduce una nuova funzionalità: metadati tempdb ottimizzati per la memoria. Questa funzionalità rimuove in modo efficace il collo di bottiglia derivante dall’evento descritto sopra. In SQL Server 2019 le tabelle di sistema coinvolte nella gestione dei metadati delle tabelle temporanee possono essere spostate in tabelle ottimizzate per la memoria non durevoli senza latch.
Per abilitare questa funzionalità, eseguire il seguente script:

dopo occorrerà riavviare il servizio per rendere effettiva la modifica.
Per verificare se il tempDB è ottimizzato per la memoria è possibile usare il seguente codice:

Prima di abilitare tale funzione invito comunque ad approfondire il tema.
Cosa succede se il tempDB ha esaurito lo spazio?
Se si esaurisce lo spazio su disco del tempDB è molto probabile che le applicazioni non siano più in grado di completare le loro operazioni, di conseguenza occorre monitorare bene lo spazio utilizzato dal tempDB.
Le seguenti query ci permettono di effettuare un primo check sullo spazio del tempDB:

Sempre ai fini di monitoraggio, oltre ad utilizzare la DMV già vista sys.dm_db_session_space_usage si può utilizzare sys.dm_db_task_space_usage; entrambe queste DMV permettono di avere informazioni sulle query, tabelle temporanee o variabili di tabella che usano una grande quantità di spazio su disco in tempDB.
Il seguente codice ci permette invece di identificare lo spazio utilizzato dagli oggetti interni in tutte le attività attualmente in esecuzione in ogni sessione:

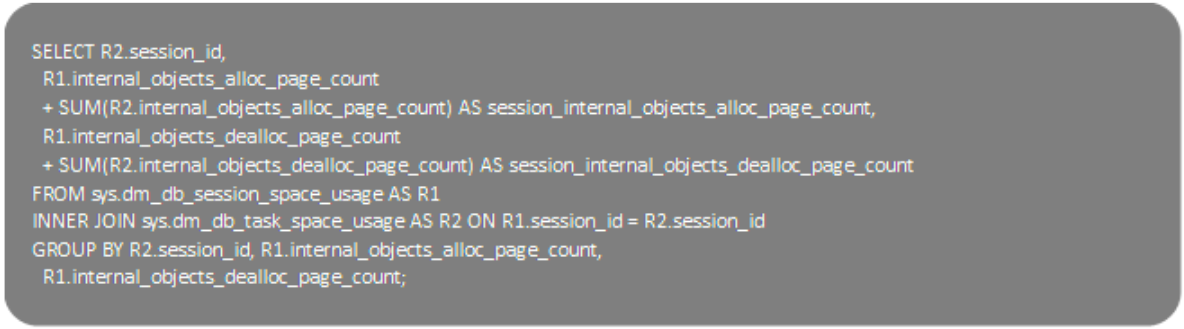
Mentre la query sotto, mostra lo spazio utilizzato dagli oggetti interni nella sessione corrente, per le attività completate ed in esecuzione:
Se nonostante tutto, il nostro tempDB ha esaurito lo spazio a disposizione è il momento di riportarlo in una condizione ottimale per permettere il corretto funzionamento delle applicazioni che fanno riferimento alla nostra istanza.
La domanda adesso è: come faccio a ridurre il mio tempDB?
Un riavvio di SQL Server riallocherebbe il tempDB secondo configurazione, ma non sempre è possibile effettuare un riavvio, di conseguenza, la prima cosa che ci salta in mente è quella di effettuare uno shrink del tempDB, quindi lanceremo il comando:

Ma cosa occorre fare se a seguito del comando sopra non si riesce a ridurre il tempDB?
Possiamo provare a lanciare il seguente comando:

Questo comando svuoterà gli indici e le pagine di dati contenute nella cache, ed è già probabile che il nostro tempDB si sia ridotto, ma ancora, un altro comando ci viene in aiuto, nel caso ancora non riuscissimo nell’intento:

Quello che c’è da sapere su quest’ultimo comando è che cancellerà tutti i piani presenti nella cache di conseguenza potremmo avere qualche rallentamento subito dopo l’esecuzione, poiché la cache dovrà essere nuovamente ricostruita, di conseguenza consiglio di lanciare questo comando se si è arrivati al punto di non ritorno.
Conclusioni
Abbiamo visto cosa è il tempDB, come SQL Server lo usa, i possibili problemi legati alla concorrenza ed allo spazio allocato ed adesso sappiamo cosa dobbiamo fare quando il nostro tempDB satura lo spazio disponibile bloccando applicazioni e le queries degli utenti.
Come DBA possiamo intervenire sulla configurazione, cercando il giusto compromesso tra numero di datafiles, spazio allocato e dischi dedicati, ma la vera ottimizzazione per un tempDB in salute deriva (quasi) sempre da un codice ben sviluppato, facendo riferimento alle best practice si Microsoft di cui abbiamo fatto solo un piccolo riferimento in questo articolo.
di Luciano Maugeri, pubblicato il 17 aprile 2025
Ti serve aiuto con SQL Server?
Prenota un incontro con i nostri esperti e scopri come possiamo aiutarti ad ottenere il massimo dalla tua infrastruttura database.