Chi ha avuto a che fare con tuning e analisi di performance, si sarà sicuramente scontrato con il wait type CXPacket. In questo articolo cercheremo di conoscerlo meglio per capire come e se tentare di ridurlo.
CXPacket
CXPacket è direttamente correlato all’esecuzione parallela di una query; detto in altre parole significa: un’istruzione viene scomposta in thread più piccoli in modo che ognuno di questi venga elaborato da una CPU (fisica o logica) separata; il completamento dell’istruzione principale viene etichettato come concluso, quando tutti i thread sono stati completati. Il piano serializzato, di contro, viene eseguito da un’unica CPU.
CXPacket (Class Exchange Packet), deve essere inteso come un indicatore, informa che l’ istanza utilizza piani paralleli per l’elaborazioni di query complesse e di conseguenza produce risultati più performanti. Questa affermazione è vera fino a quando però il parallelismo non diventa lui stesso un collo di bottiglia. Ma quando i valori di CXPacket devono allarmare e quando decidere di mettere in campo azioni risolutive affinché il parallelismo funzioni nella maniera corretta?
Query Optimizer
Query Optimizer ha un compito molto importante, che è quello di trovare il modo migliore (quindi veloce) per recuperare i dati e, per far questo cerca un piano “buono” e lo utilizza; il termine “buono” è stato volutamente utilizzato, in quanto il piano scelto non è detto che sia il migliore tra tutti, ma è quello che ha un rapporto migliore tra ricerca del piano stesso e tempo di esecuzione.
Query optimizer si basa sul cosiddetto concetto di Costo per calcolare le diverse opzioni del piano, e se ci sono tutti gli estremi (vedremo più avanti), decide di promuovere la query ad un piano parallelo.
In ogni caso l’ottimizzatore potrà scegliere un piano parallelo solo se si verificano le seguenti condizioni:
- il server è dotato di più processori
- il MAXDOP consente piani paralleli
- il costo del piano parallelo è più conveniente di un piano seriale
- il valore dell’opzione Cost threshold for Parallelism è impostata con un valore inferiore alla stima del costo per il piano attuale.
Ecco quindi che un piano parallelo è un qualsiasi piano per il quale l’ottimizzatore ha scelto di suddividere un’istruzione in più thread eseguiti in parallelo, i singoli thread vengono eseguiti da più CPU (dipendente dal numero di core) ed è il motore che determina il numero ottimale di thread e suddivide l’esecuzione del piano parallelo tra i thread stessi.
L’esecuzione parallela si serve di “particolari oggetti” per far sì che il processo funzioni in maniera ottimale, e gli attori di questo processo sono raffigurati nello schema seguente:
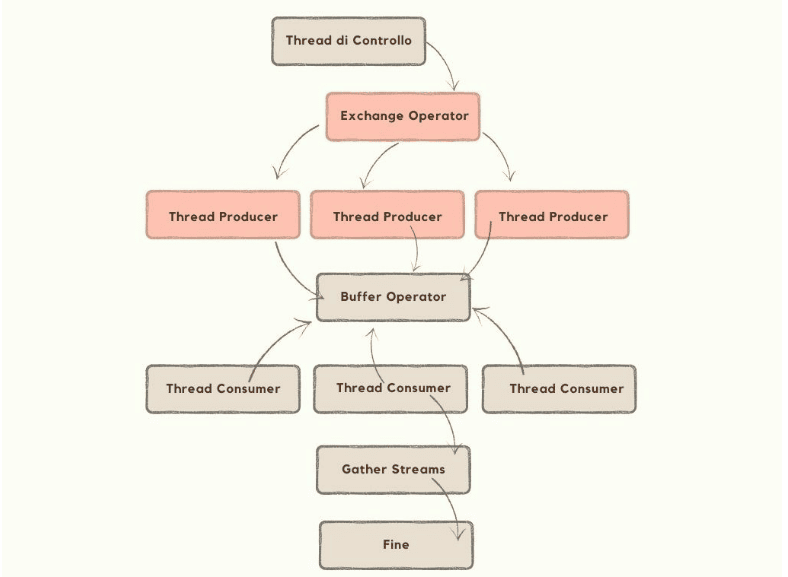
Il Thread di Controllo è deputato al coordinamento dell’esecuzione parallela della query e raccoglie il wait type CXPacket. I thread di controllo analizzano la query complessa e la suddividono in più parti che possono essere eseguite in parallelo. Inoltre dopo aver suddiviso la query, distribuisce i sotto-compiti ai thread producer ed assicura che il carico di lavoro sia ben bilanciato tra le CPU disponibili; a seguito di ciò, sincronizza i thread di lavoro garantendo che procedano in modo coordinato e sincronizzando eventuali punti dove i risultati devono essere combinati.
L’ Exchange Operator invece coordina e trasferisce i dati tra diversi thread durante l’esecuzione parallela. Gestisce la comunicazione tra i thread producer e i thread consumer. Gli Exchange Operator sono di tre tipi: Distribute Exchange che, distribuisce i dati tra i thread consumer; Repartition Exchange che redistribuisce i dati in base ad una chiave di partizionamento specifica (nel caso, ad esempio, di operazioni come join o aggregazioni dove i dati devono essere raggruppati ed ordinati in un certo modo per poter essere elaborati); Gather Streams che raccoglie i dati elaborati dai thread consumer e li combina in un unico flusso di output.
Scorrendo ancora lo schema sopra, troviamo i Thread Producer e i Thread Consumer. I primi, suddividono l’istruzione in più sottoistruzioni che possono essere elaborate in parallelo. Ad esempio, durante la scansione di una tabella, il thread Producer può leggere blocchi di dati e distribuirli ai Thread consumer per l’elaborazione successiva.
I Thread Consumer invece sono responsabili del “consumo” o dell’elaborazione dei dati che provengono dai Thread Producer. I Thread Consumer ricevono quindi i dati suddivisi e li elaborano in maniera parallela.
Altro protagonista del parallelismo (probabilmente il più importante) è il Buffer Operator che è il componente che gestisce la memorizzazione temporanea dei dati durante l’esecuzione parallela della query. Si tratta di un componente cruciale poiché assicura che i Thread Consumer non debbano aspettare inutilmente i dati necessari. Il buffer operator riceve i dati dai thread producer, memorizzandoli temporaneamente, fino a quando i thread consumer sono pronti per elaborarli. Quando i thread consumer richiedono i dati, il buffer operator li fornisce permettendo quindi una continua elaborazione parallela.
In questo sistema ciò che può alterare il normale funzionamento del parallelismo potrebbe essere generato da:
- Squilibrio del carico di lavoro nel caso in cui i compiti non sono distribuiti uniformemente tra i thread, portando ad un sovraccarico di alcuni thread a discapito di altri
- Contese di risorse di CPU, memoria, I/O. Questo può portale ad un mancato riempimento del buffer lasciando i Thread Consumer in attesa.
- Il buffer risulta pieno e di conseguenza i Thread Producer non possono scaricare i dati, poiché i Thread Consumer hanno un’elaborazione particolarmente lenta.
- Latenza di sincronizzazione, ossia del tempo necessario per sincronizzare i thread quindi questi devono attendersi l’uno con l’altro.
- Problemi di memoria, poichè l’allocazione inefficiente della memoria tra i thread può causare l’esaurimento della memoria stessa o eccessivo swapping
- Deadlock: situazione in cui due o più thread si bloccano a vicenda.
- Query non complesse che comunque vengono promosse all’esecuzione parallela e che quindi divengono più costose in confronto ad un eventuale piano serializzato.
Come detto CXPacket è un indicatore, ma in determinati casi, l’alto valore di questo wait type, può indicare che il parallelismo non funzioni in maniera ottimale. Le cause possono racchiudersi in query inefficaci poiché la richiesta di molte risorse porta ad aumentare attese, Statistiche non aggiornate che portano query optimizer a fare scelte non ottimali, configurazione errata del Max Degree for Parallelism o del MAXDOP.
Se il valore di CXPacket supera il 50 % degli altri tipi di attesa, questo rappresenta già un primo allarme. Inoltre se insieme a questa elevata percentuale di attese CXPacket si riscontrano anche attese di tipo SOS_SCHEDULER_YIELD, PAGEIOLATCH e LATCH è opportuno considerare l’implementazioni di azioni correttive.
COST THRESHOULD FOR PARALLELISM
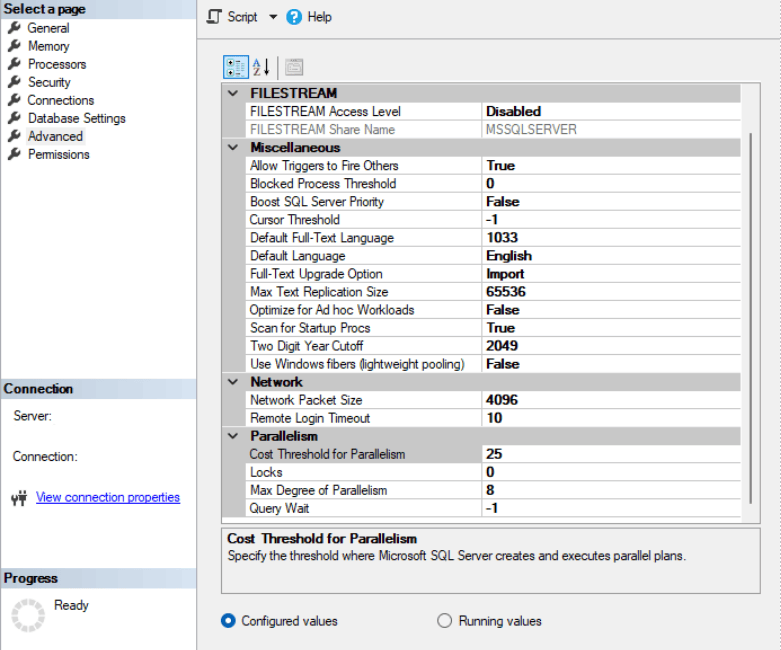
Entra qui in gioco la prima opzione che potrebbe risultare vantaggiosa, se configurata opportunamente: parliamo del Cost Threshold for Parallelism. Questa opzione di SQL Server rappresenta il valore in secondi che SQL Server stima, in termini di costo di una determinata query eseguita con piano serializzato, in modo da promuovere la stessa ad una esecuzione parallela. Questo parametro può assumere valori che vanno da 5 a 200 ed il valore di default è 5. In poche parole, se SQL Server calcola per una query un costo di 6 secondi, questa sarà promossa al parallellismo. Il valore di default molto spesso non è la scelta ottimale e generalmente tale valore viene modificato inserendo un numero di secondi più alto, risultato in ogni caso di un’analisi preventiva sulle queries che girano nell’istanza. In prima battuta si potrebbe portare il valore a 25 per poi portarlo a 50 nel caso in cui tale valore sia compatibile con l’analisi effettuata preliminarmente sul carico di lavoro.
EXEC sp_configure 'show advanced options' ,1; GO RECONFIGURE WITH OVERRIDE; GO EXEC sp_configure 'Cost Threshold for Parallelism' ,25; GO RECONFIGURE WITH OVERRIDE; GO
MAXDOP (MAX DEGREE OF PARALLELISM)
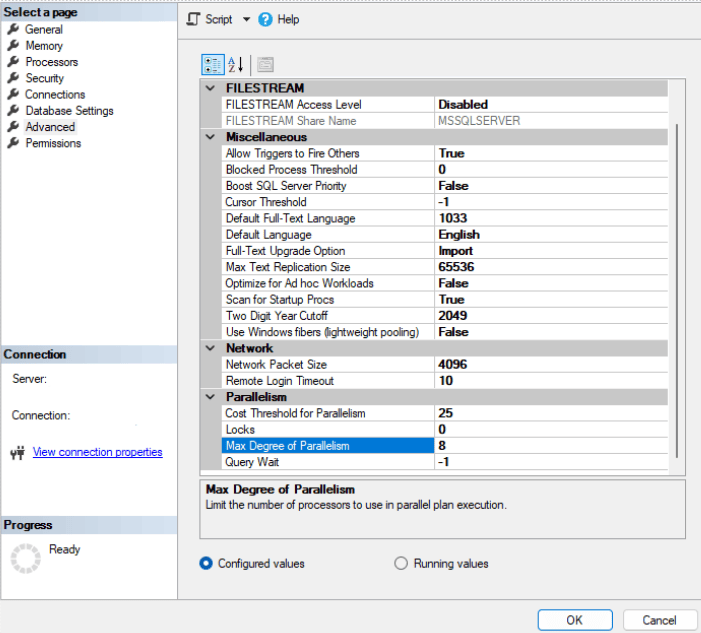
Se a seguito della modifica del CTFP (Cost Threshold for Parallelism) i valori di CXPacket risultano ancora troppo elevati, bisogna considerare l’idea di operare su un’altra opzione di SQL Server, il MAXDOP (Max Degree of Parallelism). Tramite questa opzione è possibile indicare a SQL Server quanti processori utilizzare per l’esecuzione parallela di query.
Prima dell’arrivo di SQL Server 2016 Il valore di default di questo parametro era 0 (zero), il che significa che tutti i processori sono deputati all’esecuzione parallela di query. Tale valore però non è sempre la scelta migliore e Microsoft stessa suggerisce di utilizzare la seguente tabella come guida alla configurazione, a partire da SQL Server 2016:
| Numero di processori | Linee guida |
|---|---|
| <= 8 CPU logiche | MAXDOP =< 8 |
| > 8 CPU logiche | MAXDOP = 8 |
| <= 16 CPU logiche | MAXDOP =< 16 |
| > 16 processori logici | MAXDOP = valore pari alla metà del numero di CPU logiche senza superare il valore di 16 |
L’impostazione del MAXDOP richiede comunque un’analisi preventiva e dipende dal carico di lavoro dell’istanza; occorre quindi monitorare l’istanza per verificare i valori di CXPacket a seguito di modifiche sul valore del MAXDOP e correggere eventualmente il valore assegnato.
Per impostare un valore all’opzione e possibile eseguire:
sp_configure 'show advanced options' ,1; GO RECONFIGURE WITH OVERRIDE; GO sp_configure 'max degree of parallelism' ,8; GO RECONFIGURE WITH OVERRIDE; GO
CXCONSUMER – I parenti stretti del CXPACKET
Non possiamo non fare un breve cenno al wait type CXConsumer. Possiamo definirlo il parente stretto di CXPacket poiché anch’esso si accumula in caso di parallelismo e deriva da una scomposizione di CXPacket. E’ stato introdotto con SQL Server 2016 SP2 e si accumula quando i thread Consumer attendono di elaborare i dati prodotti dai thread Producer. Grazie all’introduzione di questo wait type, adesso risulta più semplice distinguere le attese dovute dai thread Producer e quelle generate dai thread Consumer. CXCONSUMER sono del tutto normali in quegli ambienti dove ci sono delle esecuzioni parallele e, in parole semplici, rappresentano i momenti in cui i thread Consumer sono in attesa di elaborare i dati.
Anche se la presenza di queste attesa è normale, una misurazione eccessiva potrebbe indicare che i thread Consumer sono sovraccarichi o che il carico di lavoro non è distribuito i modo ottimale.
Un nuovo alleato su cui contare: FEEDBACK MAXDOP
Con l’arrivo di SQL Server 2022 viene introdotta una nuova funzionalità: DEGREE OF PARALLELISM FEEDBACK (Feedback DOP). In pratica questa funzionalità esamina le query parallele e determina se potrebbe funzionare meglio con un grado di parallelismo inferiore a quello attualmente utilizzato. Scopo di questa nuova funzionalità è risolvere l’utilizzo non ottimale del parallellismo per la ripetizioni delle query evitando interventi di configurazione manuale. Feedback DOP auto-aggiusta il DOP per evitare parallelismo eccessivo, quindi se viene rilevato un parallelismo inefficiente, feedback DOP abbassa automaticamente il DOP (il valore di MAXDOP viene sempre abbassato ma mai alzato oltre il valore impostato nell’opzione MAXDOP).
Per abilitare feedback DOP bisogna eseguire il seguente comando:
ALTER DATABASE SCOPED CONFIGURATION SET DOP_FEEDBACK = ON;
La query seguenti lo disabilita:
ALTER DATABASE SCOPED CONFIGURATION SET DOP_FEEDBACK = OFF;
Da notare che il Feedback DOP riguarda solo le query che operano nel livello di compatibilità 16.0 o versione successiva.
Se il DOP modificato determina una regressione delle prestazioni, il feedback del DOP tornerà all’ultimo DOP valido conosciuto, attenzione perché anche una query annullata dall’utente viene percepita come una regressione.
Il feedback stabile viene nuovamente verificato al momento della ricompilazione del piano e potrebbe essere regolato verso l’alto o verso il basso, ma mai superiore all’impostazione MAXDOP.
Conclusioni
CXPacket è un ottimo indicatore per il monitoraggio del parallelismo e dei meccanismi che lo rendono possibile. Il parallelismo può migliorare le prestazioni delle query, ma è necessario gestirlo per evitare problemi di contesa risorse, latenza o squilibrio del carico. Le attese CXPacket di conseguenza non sono necessariamente un problema, ma possono indicare inefficienze nel modo in cui le query vengono eseguite in parallelo. Monitorare quindi, le attese CXPacket, permette di prendere le misure appropriate per migliorare significativamente le prestazioni del database.
di Luciano Maugeri, pubblicato il 02/10/2024