La Collation in SQL Server è una componente cruciale che definisce il comportamento delle operazioni di confronto, ricerca e di ordinamento dei dati di tipo alfanumerico all’interno dell’ambiente di lavoro.
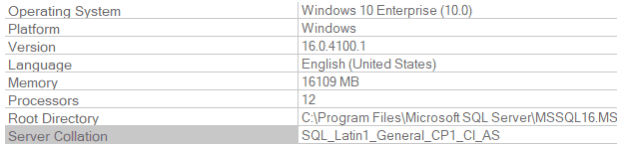
Fig 1. Dettaglio delle proprietà di istanza con evidenziata la collation
Consiste in un insieme di regole e impostazioni che determinano come i caratteri vengono interpretati durante pressoché ogni fase di elaborazione e manipolazione degli stessi.
Esistono decine di Collation diverse che definiscono altrettanti comportamenti riguardo in particolare lettere maiuscole e minuscole, accentate e non, e generalmente la corretta interpretazione dei caratteri.
Durante l’installazione di SQL Server va scelta la Collation che definirà a livello di istanza le regole.
SQL Server ne propone una diversa a seconda della lingua del sistema operativo:
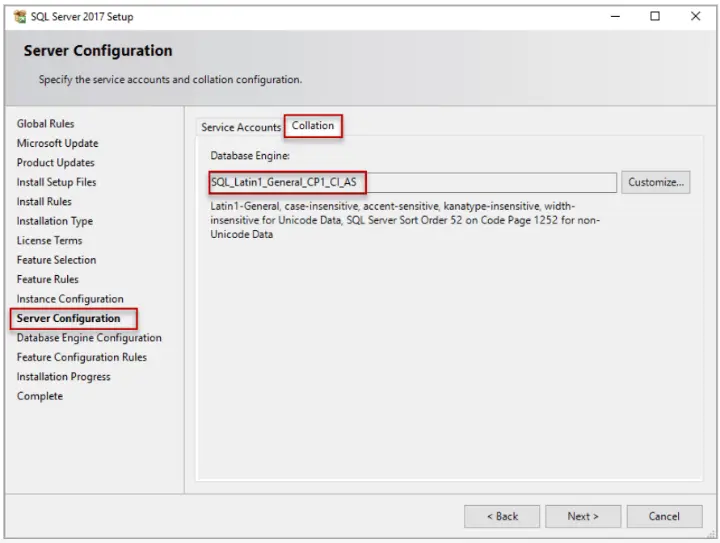 Fig. 2 Impostazione della Collation durante l’installazione di SQL Server
Fig. 2 Impostazione della Collation durante l’installazione di SQL Server
L’esempio mostra l’impostazione predefinita per la lingua inglese.
La prima parte del nome definisce il set di caratteri di codifica (in questo caso ‘Latin1’ cioè quelli occidentali) mentre la seconda il comportamento in caso di lettere maiuscole (‘CI’ = case insensitive ovvero nessuna differenza logica fra lettere maiuscole e minuscole) e in caso di lettere accentate (‘AS’ = accent sensitive, ovvero differenza logica fra lettere accentate e non).
Una volta definita essa sarà la Collation di default di tutti gli oggetti creati all’interno dell’istanza.
La lista completa dei vari nomi e del significato delle sigle è disponibile qui:
Windows_collation_name (Transact-SQL) - SQL Server | Microsoft Learn
NOTA BENE: cambiare la Collation a installazione eseguita è un procedimento dispendioso e altamente sconsigliabile, vedi:
Impostazione o modifica di regole di confronto del server - SQL Server | Microsoft Learn
Una volta definita la Collation a livello di istanza, è possibile cambiarla per ogni database e anche per ogni colonna all’interno delle singole tabelle usando l’istruzione COLLATE.

Fig. 3 Definizione di diverse collation per database e tabella in fase di creazione
La stessa istruzione viene usata per i confronti e gli ordinamenti all’interno delle tabelle.

Fig. 4 COLLATE durante ordinamento
Usando il comando ALTER TABLE o ALTER DATABASE è possibile modificare la Collation in uso a livello di colonna.

Fig. 5 COLLATE e ALTER DATABASE
Ricapitolando, i livelli possibili di Collation sono quindi tre:
- Istanza
- Database
- Colonna
Ed è sempre possibile un confronto corretto fra i dati utilizzando il comando COLLATE.
CONSIDERAZIONI GENERALI:
- Scegliere la collation in base al contesto.
Valutare le esigenze linguistiche e culturali dell’applicazione, ricordando che è necessario che i dati siano letti correttamente e che la trasmissione degli stessi ad eventuali altri componenti sia efficace. La Collation può influenzare anche le performance (vedi: Supporto Unicode e delle regole di confronto - SQL Server | Microsoft Learn).
- Evitare comportamenti ambigui.
Assicurarsi che a livello di query la collation sia omogenea, ad esempio evitando di usarne una case-insensitive ed un altra case-sensitive mentre si confrontano i dati.
- Impostare Collation a livello di database o colonna solo se necessario.
Questo garantisce omogeneità nei dati e limita possibili fraintendimenti. È buona norma inoltre utilizzare tipologie di dati che supportano lo standard Unicode (es. Nvarchar)
- Attuare rigide politiche di importazione dei dati da fonti esterne per limitare incoerenze.
PROBLEMATICHE COMUNI:
- Confronti errati ed ordinamenti incoerenti.
Discrepanze nei livelli di Collation possono portare ad errori nei confronti e negli ordinamenti generando comportamenti inaspettati o imprevisti nelle query, limitando l’utilizzabilità stessa dell’applicazione.
- Join inefficaci.
Confrontare dati codificati in maniera diversa rende le join praticamente inutilizzabili. Utilizzare una conversione esplicita se due colonne hanno diversa Collation.
- Visualizzazione errata dei dati.
Gli stessi dati letti in due modi diversi possono generare problemi nella visualizzazione da parte dell’utente finale.
- Violazione dei vincoli di integrità.
Codifiche errate possono portare a violazione della convalida degli stessi causando errori.
Conclusioni
In conclusione, la Collation è un aspetto da tenere ben presente quando si utilizza SQL Server e che può assumere enorme rilevanza a seconda del contesto. Eventuali discrepanze nei dati possono essere molto difficili da individuare e possono inficiare di molto le performance generali.
di Niccolò Albizzati, pubblicato il 18 aprile 2024
Hai bisogno di aiuto con SQL Server?
Non aspettare che i problemi si accumulino: siamo qui per ascoltarti e aiutarti. Che si tratti di ottimizzare i tuoi database, risolvere un rallentamento o costruire una strategia su misura, la soluzione inizia con una chiacchierata.
Contattaci oggi stesso: rispondiamo in fretta e parliamo la tua lingua, senza complicazioni