In questo articolo esploreremo l’architettura generale di PostgreSQL, analizzando sia la struttura logica che quella fisica di un database cluster per poi approfondire l’architettura dei processi e la gestione della memoria. Questo approfondimento ci permetterà di comprendere meglio come è strutturato PostgreSQL e, implicitamente, fare i dovuti confronti con l’architettura di SQL Server, di cui siamo confidenti.
Struttura logica del Database Cluster
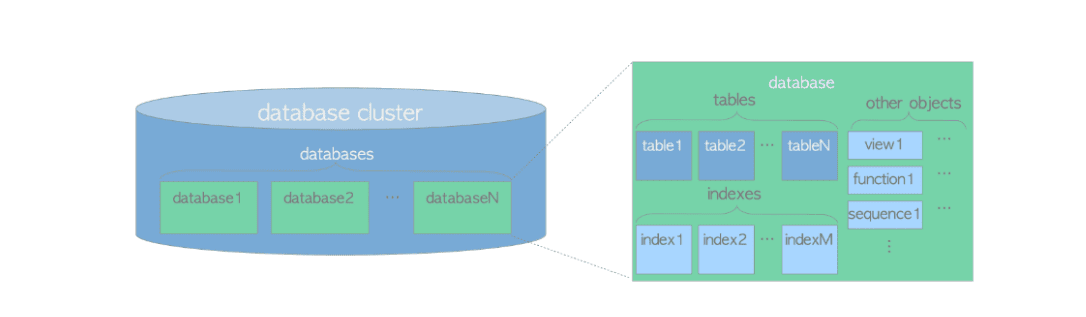
Un database cluster è un insieme di database gestiti da un singolo server PostgreSQL. Ogni cluster contiene uno o più database, e ogni database è costituito da una serie di oggetti come tabelle, viste, indici, funzioni e sequenze.
- Database Cluster: è l’unità principale di gestione in PostgreSQL. Un cluster può contenere più database, ma ogni database è isolato dagli altri.
- Databases: all’interno di un cluster, ogni database è indipendente e ha il proprio set di oggetti. Questo isolamento permette una gestione sicura e organizzata dei dati.
Struttura fisica del Database Cluster
Dal punto di vista fisico, un database cluster è fondamentalmente una singola directory, denominata base directory. Questa directory contiene alcune sottodirectory e diversi file. Il percorso della base directory è solitamente impostato sulla variabile di ambiente PGDATA.
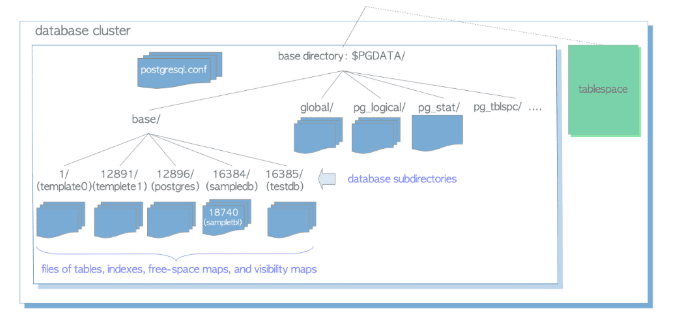
La directory principale di un database cluster contiene diverse sottodirectory tra le quali:
- base/: contiene le directory per ogni database nel cluster. Tutti i database e gli oggetti legati ai database sono definiti tramite un OID (object identifier), un numero intero di 4 bytes
- global/: contiene i file che memorizzano informazioni globali del cluster, come le tabelle di sistema.
- pg_stat/: contiene file dove sono raccolte le statistiche di sistema
- pg_xlog/ o pg_wal/: contiene i file di log delle transazioni.
- pg_tblspc/: contiene i collegamenti simbolici ai tablespace.
Esistono poi alcuni file particolarmente importanti da segnalare:
- postgresql.conf: file di configurazione principale di PostgreSQL, dove si possono configurare tutte le principali impostazioni del database cluster.
- pg_hba.conf: file di configurazione per il controllo degli accessi.
- pg_ident.conf: file di mappatura degli utenti.
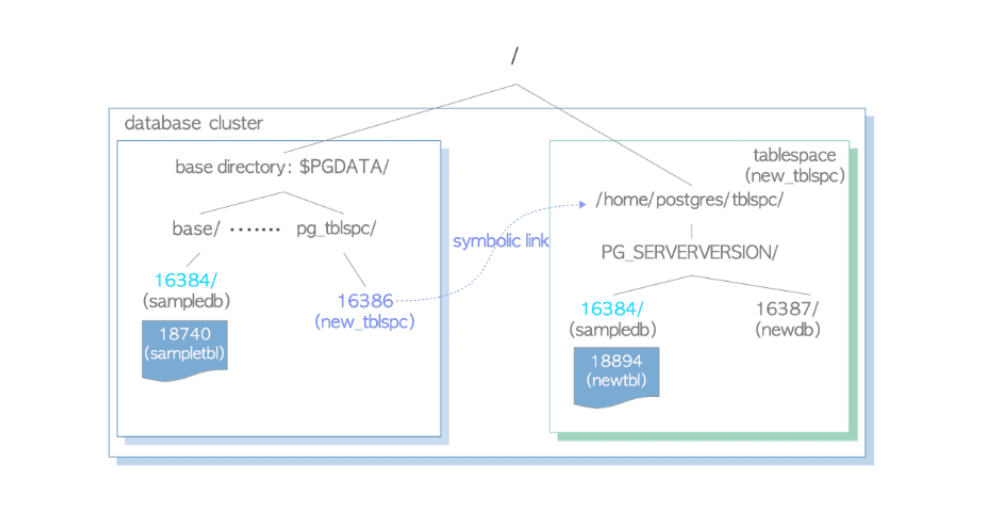
Esiste poi il concetto di Tablespace che rappresenta, a livello di file system, un’area al di fuori della base directory dove poter salvare nuovi oggetti (database, tabelle, indici etc etc). Tipicamente viene utilizzata quando si vuole salvare questi oggetti su mount point (storage) diversi da quello della base directory, sia per motivi di spazio sia per motivi di performance.
Processi di PostgreSQL
PostgreSQL utilizza un’architettura a processi multipli per gestire le operazioni verso il database cluster. Ogni connessione al database è gestita da un processo separato.
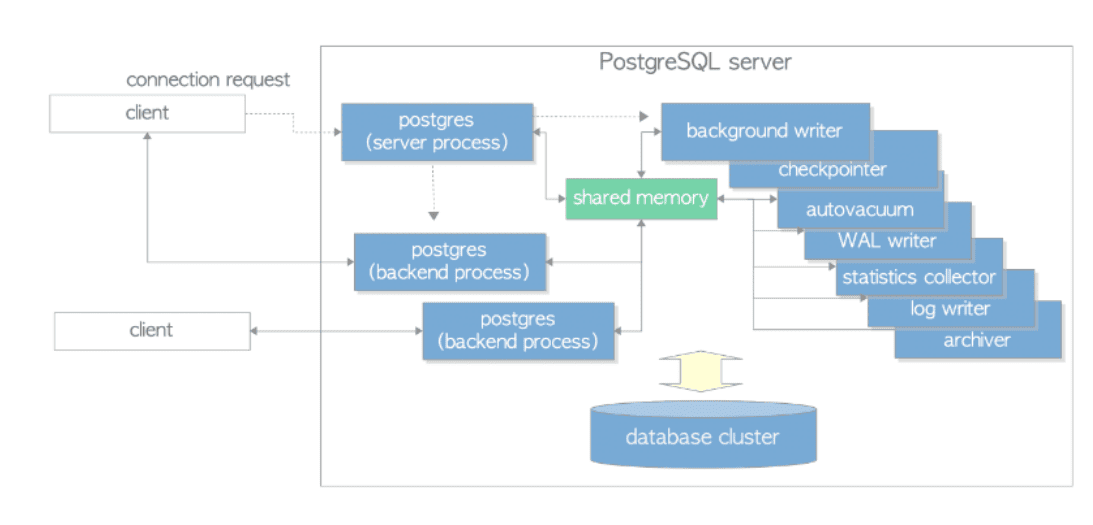
Server process
Il postgres server processè il padre di tutti i processi. La sua funzione è di allocare uno spazio di memoria condivisa (shared memory), avviare i principali processi di background e attendere le connessioni da parte dei client. Ogni volta che riceve una richiesta di connessione da un client, avvia un sotto processo chiamato backend process, il cui scopo è di soddisfare tutte le query che arrivano dal client connesso.
Backend process
Un postgres backend process viene avviato ogni volta che il postgres server process riceve una richiesta di connessione da parte di un client, la sua funzione è soddisfare tutte le richieste che arrivano dal client (tramite connessione tcp) e termina quando il client si disconnette. Il numero di client che si possono connettere ad un server PostgreSQL in modo simultaneo è definito dal parametro max_connections nel file postgresql.conf.
Background processes
Il server process avvia una serie di background processes, ognuno con una specifica funzione. Vediamone i principali:
- background writer: è il processo dedicato a scrivere le dirty pages dalla memoria condivisa (shared buffer pool) verso lo storage (file fisico su disco).
- checkpointer: è il processo dedicato ad eseguire il checkpoint a intervalli predefiniti.
- autovacuum launcher: questo processo periodicamente chiede al postgres server process di avviare i workers dedicati all’attività di autovacuum.
- WAL writer: è il processo dedicato a scrivere e liberare i dati presenti nel WAL buffer verso lo storage (file fisico su disco).
- statistics collector: è il processo dedicato a raccogliere informazioni di statistiche.
- logging collector: è il processo dedicato a scrivere eventuali messaggi di errore nei file di log.
- archiver: è il processo dedicato ad archiviare i WAL files.
Memoria di PostgreSQL
L’architettura della memoria in PostgreSQL si può suddividere in 2 categorie:
- Area di memoria locale: è quella quota di memoria allocata da ciascun backend process per poter processare le query che arrivano dal client.
- Area di memoria condivisa: è quella quota di memoria usata da tutti i processi che compongono un server PostgreSQL.
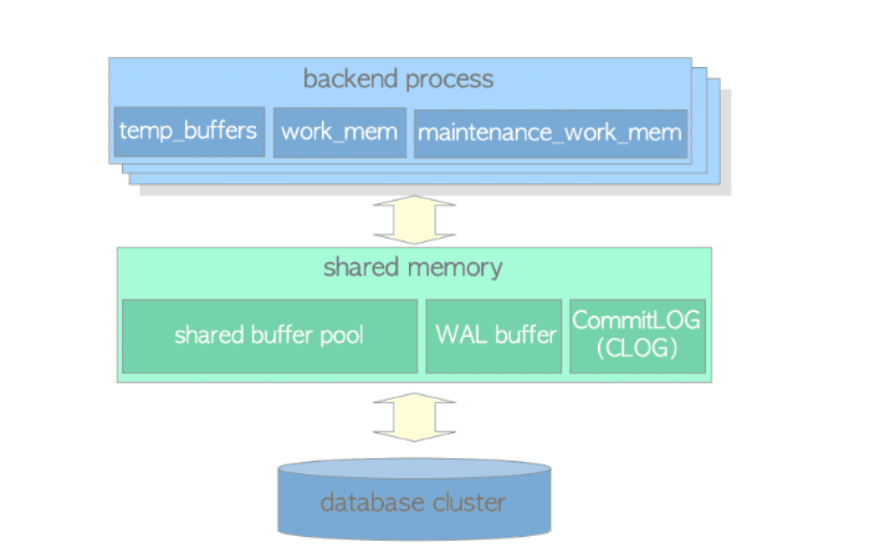
L’area di memoria locale a sua volta si suddivide in alcune sotto-aree
- work_mem: area dedicata ad operazioni di ordinamento (ORDER BY e DISTINCT) e di join (hash e merge join).
- maintenance_work_mem: area dedicate ad operazioni di manutenzione (vacuum, reindex).
- temp_buffer: area dedicata a oggetti temporanei (temp tables).
Anche l’area di memoria condivisa si suddivide in alcune sotto-aree:
- shared_buffer_pool: area dedicate ad ospitare le pagine di dati lette da disco.
- WAL buffer: è quell’area di memoria dedicata a registrare i dati di WAL coprima che essi vengano resi persistenti su disco.
- Commit log: area dedicata a tenere traccia dello stato delle transazioni (in progress, committed, aborted) per il meccanismo di concorrenza (MVCC) di PostgreSQL.
Conclusioni
L'architettura di PostgreSQL è progettata per essere robusta, scalabile e flessibile. Si tratta inoltre di un’architettura estremamente configurabile: gran parte delle impostazioni possono essere configurate direttamente a partire dal file postgresql.conf (tale argomento merita un articolo a se stante).
Comprendere la struttura logica e fisica del database, l’architettura dei processi e la gestione della memoria è fondamentale per ottimizzare le prestazioni e garantire la sicurezza dei dati.
di Matteo Dal Bianco, pubblicato il 13 febbraio 2025