Ogni database SQL Server dispone di almeno due file nel sistema operativo: un file di dati e un file di log (transaction log). I file di dati contengono dati e oggetti come tabelle, indici, procedure e viste. I file di log contengono le informazioni necessarie per ripristinare tutte le transazioni nel database. I file di dati possono essere raggruppati in filegroup per scopi di allocazione ed amministrazione.
Database Files
I database SQL Server dispongono di tre tipi di file, come illustrato nella tabella seguente.
| File | Descrizione |
|---|---|
| Primario | Contiene informazioni di avvio per il database e punta agli altri file nel database. Ogni database ha un file di dati primario. L'estensione del nome file consigliata per i file di dati primari è .mdf. |
| Secondario | File di dati (opzionali) definiti dall'utente. I dati possono essere distribuiti su più dischi inserendo ciascun file su un'unità disco diversa. L'estensione del nome file consigliata per i file di dati secondari è .ndf. |
| Transaction log | Il log contiene le informazioni utilizzate per ripristinare il database. Deve essere presente almeno un file di registro per ciascun database. L'estensione del nome file consigliata per i registri delle transazioni è .ldf. |
Per impostazione predefinita, i dati e i transaction log vengono inseriti nello stesso disco e percorso, per gestire i sistemi a disco singolo. Questa scelta potrebbe non essere ottimale per gli ambienti di produzione: è infatti consigliato inserire i file di dati e i file di log su dischi separati.
Logical and Physical File Names
I file di SQL Server hanno due tipi di nomi file:
- logical_file_name: il nome di file logico è il nome utilizzato per fare riferimento al file fisico in tutte le istruzioni Transact-SQL. Il nome del file logico deve essere conforme alle regole per gli identificatori di SQL Server e deve essere univoco tra i nomi di file logici all’interno del database.
- os_file_name: è il nome del file fisico incluso il percorso della directory. Deve seguire le regole per i nomi dei file del sistema operativo.
Per ulteriori informazioni sugli argomenti NOME e NOME FILE, vedere ALTER DATABASE File and Filegroup Options (Transact-SQL).
TIP: I file di dati e transaction log di Sql Server possono essere scritti nei file system FAT o NTFS. Sui sistemi Windows Microsoft consiglia di utilizzare il file system NTFS a causa degli aspetti di sicurezza di NTFS.
TIP: È una buona idea mantenere le estensioni di file predefinite. Non ci sono veri vantaggi nell'usare estensioni diverse e farlo aggiunge ulteriore complessità. Ad esempio, non solo occorre ricordare quali estensioni sono state usate, ma anche, se il software antivirus usa estensioni di file per il suo elenco di esclusioni, potrebbe verificarsi improvvisamente un brutto calo nelle prestazioni.
WARNING: I filegroup di dati e transaction log in lettura/scrittura non sono supportati su un file system NTFS compresso. Solo i database di sola lettura e i filegroup secondari di sola lettura possono essere inseriti in un file system NTFS compresso. Per risparmiare spazio, si consiglia vivamente di utilizzare la compressione dei dati anziché la compressione del file system.
Quando più istanze di SQL Server sono in esecuzione su un singolo computer, ogni istanza riceve una directory predefinita diversa per contenere i file per i database creati nell'istanza. Per ulteriori informazioni, vedere File Locations for Default and Named Instances of SQL Server.
Data file pages
Le pagine in un file di dati di SQL Server sono numerate in sequenza, a partire da zero (0) per la prima pagina del file. Ogni file in un database ha un numero ID file univoco. Per identificare in modo univoco una pagina in un database, sono richiesti sia l'ID file che il numero di pagina. L'esempio seguente mostra i numeri di pagina in un database che dispone di un file di dati primario da 4 MB e di un file di dati secondario da 1 MB.
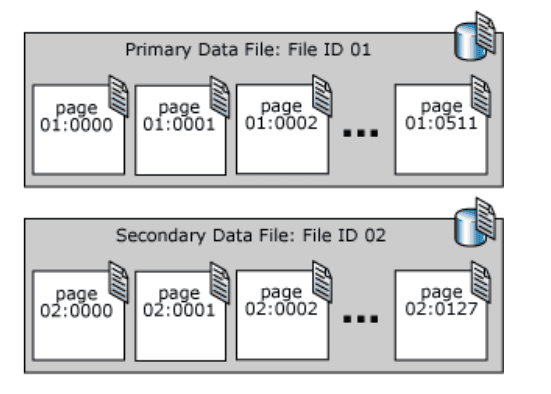
Una pagina di intestazione del file è la prima pagina che contiene informazioni sugli attributi del file. Molte delle altre pagine all'inizio del file contengono anche informazioni di sistema, come le mappe di allocazione. Una delle pagine di sistema memorizzate sia nel file di dati primario che nel primo file di log è una pagina di avvio del database che contiene informazioni sugli attributi del database.
File Size
I file di SQL Server possono aumentare automaticamente rispetto alla dimensione specificata originariamente. Quando si definisce un file, si può specificare un incremento di crescita specifico. Ogni volta che il file viene si riempie aumenta le sue dimensioni in base all'incremento specificato. Se in un filegroup sono presenti più file, le dimensioni non aumenteranno automaticamente finché tutti i file non saranno riempiti.
Per ogni file può anche essere specificata una dimensione massima. Se non viene specificata una dimensione massima, il file può continuare a crescere finché non avrà utilizzato tutto lo spazio disponibile su disco.
Capire le tipologie di spazio di archiviazione per un database
Comprendere le seguenti quantità di spazio di archiviazione è importante per la gestione dello spazio file di un database.
| Spazio database | Definizione | Note |
|---|---|---|
| Spazio dati utilizzato | La quantità di spazio utilizzata per archiviare i dati del database. | Generalmente, lo spazio utilizzato aumenta (diminuisce) durante gli insert (delete). In alcuni casi, lo spazio utilizzato non cambia negli insert o nelle delete a seconda della quantità e del tipo di dati coinvolti nell'operazione e nell'eventuale frammentazione. Ad esempio, l'eliminazione di una riga da ogni pagina di dati non diminuisce necessariamente lo spazio utilizzato. |
| Spazio dati allocato | La quantità di spazio file formattato reso disponibile per l'archiviazione dei dati del database. | La quantità di spazio allocato aumenta automaticamente, ma non diminuisce mai dopo operazioni di delete. Questo comportamento garantisce che gli inserimenti futuri siano più veloci poiché non è necessario riformattare lo spazio. |
| Spazio dati allocato ma non utilizzato | La differenza tra la quantità di spazio dati allocato e lo spazio dati utilizzato. | Questa quantità rappresenta la quantità massima di spazio libero che può essere recuperato riducendo i file di dati del database. |
| Spazio massimo utilizzabile | La quantità massima di spazio che può essere utilizzata per archiviare i dati del database. | La quantità di spazio dati allocato non può superare la dimensione massima impostata. |
Database snapshot files
Il formato del file utilizzato da uno snapshot del database per archiviare i dati copy-on-write dipende dal fatto che lo snapshot venga creato da un utente o utilizzato internamente:
- Uno snapshot del database creato da un utente memorizza i propri dati in uno o più file sparsi. La tecnologia dei file sparsi è una caratteristica del file system NTFS. Per informazioni generali sull'uso di file sparsi negli snapshot del database e su come crescono gli snapshot del database, vedere View the Size of the Sparse File of a Database Snapshot.
- Gli snapshot del database vengono utilizzati internamente da alcuni comandi DBCC. Questi comandi includono DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC e DBCC CHECKFILEGROUP. Uno snapshot del database interno utilizza stream di dati alternati sparsi dei file di database originali. Come i file sparsi, gli stream di dati alternati sono una caratteristica del file system NTFS. L'uso di stream di dati alternati sparsi consente di associare più allocazioni di dati a un singolo file o cartella senza influire sulla dimensione del file o sulle statistiche del volume.
Filegroups
- Il filegroup primario contiene il file di dati primario e tutti i file secondari che non vengono inseriti in altri filegroup.
- È possibile creare filegroup definiti dall'utente per raggruppare insieme file di dati per scopi amministrativi, di allocazione dei dati e di posizionamento.
Ad esempio: Data1.ndf, Data2.ndf e Data3.ndf possono essere creati rispettivamente su tre unità disco e assegnati al filegroup fgroup1. È quindi possibile creare una tabella specificatamente sul filegroup fgroup1. Le query per i dati della tabella verranno distribuite sui tre dischi: migliorerà le prestazioni. Lo stesso miglioramento delle prestazioni può essere ottenuto utilizzando un singolo file creato su uno stripe set RAID (array ridondante di dischi indipendenti). Tuttavia, file e filegroup consentono di aggiungere facilmente nuovi file su nuovi dischi.
Tutti i file di dati vengono archiviati nei filegroup elencati nella tabella seguente:
| Filegroup | Descrizione |
|---|---|
| Primary | Il filegroup che contiene il file primario. Tutte le tabelle di sistema fanno parte del filegroup primario. |
| Memory Optimized Data | Un filegroup ottimizzato per la memoria si basa sul filegroup filestream. |
| Filestream | Filestream. |
| User-defined | Qualsiasi filegroup creato dall'utente quando crea per la prima volta il database o quando lo modifica in seguito. |
Default (primary) filegroup
Quando gli oggetti vengono creati nel database senza specificare a quale filegroup appartengono, vengono assegnati al filegroup predefinito. In qualsiasi momento, un filegroup viene designato come filegroup predefinito. I file nel filegroup predefinito devono essere abbastanza grandi da contenere tutti i nuovi oggetti non assegnati ad altri filegroup.
Il filegroup PRIMARY è il filegroup predefinito a meno che non venga cambiato tramite l'istruzione ALTER DATABASE. L'allocazione per gli oggetti e le tabelle di sistema rimane all'interno del filegroup PRIMARY, non del nuovo filegroup predefinito.
Memory-optimized data filegroup
Per maggiori informazioni fare riferimento a: Memory Optimized Filegroup.
FILESTREAM filegroup
Per maggiori informazioni fare riferimento a: FILESTREAM e Create a FILESTREAM-Enabled Database.
Logica di riempimento di file e filegroup
I filegroup utilizzano una strategia di riempimento proporzionale su tutti i file all'interno di ogni filegroup. Quando i dati vengono scritti nel filegroup, SQL Server Database Engine scrive una quantità proporzionale allo spazio libero nel file su ogni file all'interno del filegroup, invece di scrivere tutti i dati sul primo file fino al riempimento. Quindi scrive sul file successivo.
Ciò significa che per i filegroup contenenti più di un file, non si ha alcun controllo su quale file viene utilizzato per archiviare il singolo oggetto. Infatti, poiché SQL Server alloca i dati ai file utilizzando un approccio di tipo round-robin, ogni oggetto archiviato nel filegroup ha un'alta probabilità di essere suddiviso su tutti i file all'interno del filegroup stesso.
Regole per la progettazione di file e filegroup
Le seguenti regole riguardano i file e i filegroup:
- Un file o un filegroup non può essere utilizzato da più di un database.
- Un file può essere membro di un solo filegroup.
- I file di transaction log non fanno mai parte di alcun filegroup.
Raccomandazioni
Per concludere, ecco alcun raccomandazioni da tenere presenti quando si lavora con file e filegroup:
- La maggior parte dei database funziona bene con un singolo file di dati e un singolo file di transaction log.
- Se si utilizzano più file di dati, creare un secondo filegroup per il file aggiuntivo e rendere quel filegroup il filegroup predefinito. In questo modo, il file primario conterrà solo tabelle e oggetti di sistema.
- Per massimizzare le prestazioni, creare file o filegroup su dischi diversi il più possibile. Mettere gli oggetti che utilizzano spazio in modo massivo in filegroup diversi.
- Utilizzare i filegroup per consentire il posizionamento di oggetti su dischi fisici specifici.
- Inserire tabelle diverse utilizzate nelle stesse query di join in filegroup diversi. Questo passaggio migliorerà le prestazioni, grazie alla ricerca parallela di I/O su disco per i dati in join.
- Collocare le tabelle con accesso intensivo e gli indici non cluster che appartengono a tali tabelle su filegroup diversi. L'utilizzo di filegroup diversi migliorerà le prestazioni, a causa dell'I/O parallelo se i file si trovano su dischi fisici diversi.
- Non posizionare il o i file di transaction log sullo stesso disco fisico in cui si trovano gli altri file e filegroup.
- Se c’è la necessità di estendere un volume o una partizione su cui risiedono file di database utilizzando strumenti come Diskpart, si dovrebbe prima eseguire il backup di tutti i database di sistema e utente e arrestare i servizi di SQL Server. Inoltre, una volta che i volumi del disco sono stati estesi correttamente, si dovrebbe prendere in considerazione l'esecuzione del comando DBCC CHECKDB per garantire l'integrità fisica di tutti i database residenti sul volume.
di Datamaze, pubblicato il 19 novembre 2024
Ti serve aiuto con SQL Server?
Prenota un incontro con i nostri esperti e scopri come possiamo aiutarti ad ottenere il massimo dalla tua infrastruttura database.