Cos'è un backup?
Un backup in Oracle è una copia dei dati del database che può essere utilizzata per ripristinare il database in caso di perdita di dati o errori.
Si tratta di un’attività fondamentale in quanto serve a garantire che i dati siano disponibili nel tempo e rappresentano una protezione da eventi del tipo:
- User error: a causa di un errore nella logica dell'applicazione o per l’esecuzione di un comando errato (update, delete, truncate,..) da parte dell’operatore umano, i dati nel database vengono modificati o eliminati in modo errato.
- Media failure: un problema sul supporto fisico ove risiedono i file del database.
Database Oracle: struttura fisica e concetti base
La struttura fisica del database e il ruolo che ciascun elemento riveste nel processo di backup e recovery sono gli elementi che concorrono a determinare quali tecniche di backup e recovery utilizzare.
I file e le altre strutture che compongono un database Oracle archiviano i dati e li proteggono da possibili guasti.
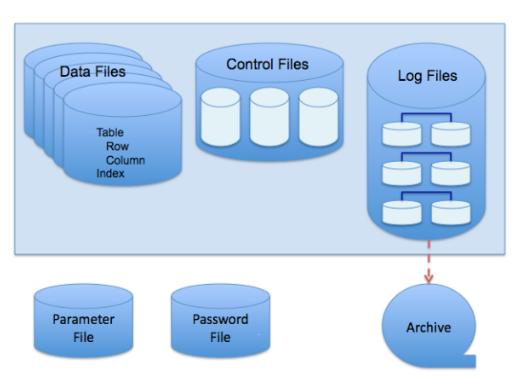
Physical Database Structures Used in Recovering Data
- Datafiles e data block. Un database Oracle consiste di una o più unità storage logiche chiamate tablespace; ciascun tablespace è costituito da uno o piu file fisici che risiedono sul sistema operativo chiamati datafiles. I dati (tabelle, indici, procedure...) risiedono sui datafile. Il database gestisce lo spazio di archiviazione nel datafile in unità chiamate data blocks.
- Control Files. Il control file contiene le informazioni relative alle strutture fisiche del database e al loro stato e diverse informazioni relative al backup e recovery.
- Redo logs. Registrano le modifiche fatte sui dati. Con un insieme completo di redolog e una vecchia copia di un datafile, il db può riapplicare tutte le modifiche registrate nei redologs per ricreare il database ad un PIT tra il momento in cui è stato eseguito il backup e l’ultima transazione sull’ultimo redolog disponibile.
- Undo segments. Quando un dato viene aggiornato viene creata un’immagine ‘before update’ così che se una trx effettua rollback, le informazioni nell’undo permettono di tornare indietro a prima dell’aggiornamento. Nel contesto della recovery, le informazioni nell’undo vengono utilizzate per annullare le trx non committate dopo che sono stati applicati i redologs ai datafiles.
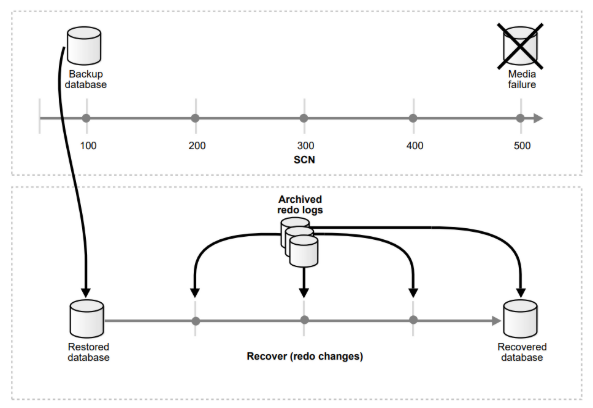
Il processo di recupero di un database: restore e recovery
Per ricostruire un database da un backup si fa riferimento a due fasi distinte: la prima consiste nel restore della copia di/dei datafile dal backup e la seconda nel recovery del database fino all’SCN desiderato riapplicando le modifiche contenute negli archive e nei redo logs.
L’SCN (System Change Number) in Oracle è un timestamp logico utilizzato per ordinare gli eventi che avvengono all’interno del database. Questo è fondamentale per mantenere la coerenza dei dati e soddisfare le proprietà ACID (Atomicità, Consistenza, Isolamento, Durabilità) delle transazioni. Viene utilizzato durante il processo di recovery per determinare fino a che punto applicare i redologs.
Tipologie di Backup Oracle
Il backup è una copia dei dati del nostro database che può essere utilizzata per ricostruire tali dati. I backups possono essere suddivisi in due categorie:
Backup fisici (rman): sono backup dei file fisici utilizzati per contenere i dati e per recoverare il database ossia datafile, controlfile e archived redolog. In definitiva, ogni backup fisico è una copia dei file che memorizzano le informazioni del database in un'altra posizione, su disco o su un dispositivo di archiviazione offline come una tape library.
Backup logici (expdp): essi contengono i dati logici (tabelle, stored procedure, trigger…) esportati attraverso l’utility export di Oracle. Tali dati sono conservati in uno o più file binari (.dmp) e sono utilizzati per essere eventualmente reimportati nel database con l’utility import.
I backup fisici sono il fondamento di qualsiasi strategia di backup e ripristino. I backup logici sono un utile complemento ai backup fisici in molte circostanze.
Tipologie di Backup Oracle con RMAN
Ci sono più modi per distinguere tra backup fisici che dipendono sia dallo stato del database quando il backup è stato eseguito, sia da quale parte del database è stata oggetto del backup, sia da come il backup risultante è stato conservato.
Consistent and Inconsistent Backups
- Backup consistenti sono quelli effettuati quando tutte le trx nei redolog sono state applicate ai datafiles. Un db così restorato può essere immediatamente aperto, senza effettuare media recovery. Tuttavia, un backup consistente può essere creato solo a fronte di uno spegnimento pulito (normal) del database (non uno shutdown abort o dopo un crash del db). Per ragioni di disponibilità h24 del servizio, Oracle è strutturato per lavorare anche con i backup iconsistenti.
- Backup inconsistenti, fatti a db aperto, pertanto dopo la fase di restore dei datafile, effettuano la recover applicando le modifiche contenute negli archived e online redo logs prima che il database sia nuovamente aperto. Sarà quindi necessario avere il database in ARCHIVELOG mode.
Full and Incremental Backups
- FULL. Include tutti i datafile che costituiscono il database; essi possono essere creati con RMAN o con comandi di copia file di sistema operativo.
- Incrementali. Salvano solo i blocchi dati dei datafile che sono stati modificati rispetto all’ultimo full.
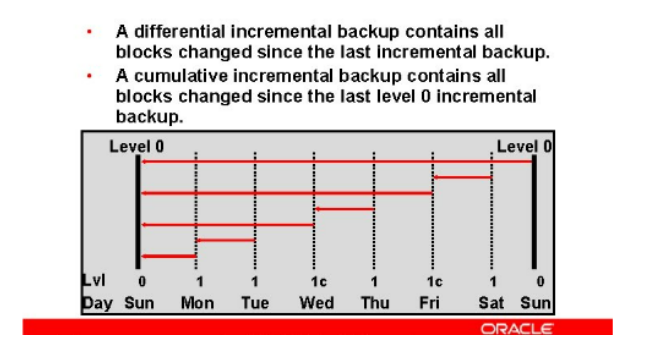
L’incrementale permette di ridurre notevolmente i tempi di recovery perché recupera i blocchi modificati rispetto al full evitando l’applicazione dei redolog. I backup incrementali possono essere creati solo con RMAN.
Image Copies, Backup Sets and Backup Pieces
Il risultato di un backup RMAN può essere sia una image copy che un backup set.
- Image copy: è una copia identica bit-per-bit dei datafile, la stessa che creerei col commando cp di Unix o il copy di Windows) con il plus però che RMAN effettua anche un check su possibile corruzione del datafile.
- Backup set: un insieme di backup piece, ciascuno contenente la copia di uno o più datafiles. Sono la sola modalità con cui RMAN può scrivere i suoi backup su media manager device come p.e. le tape libraries.
Disegno del piano di backup
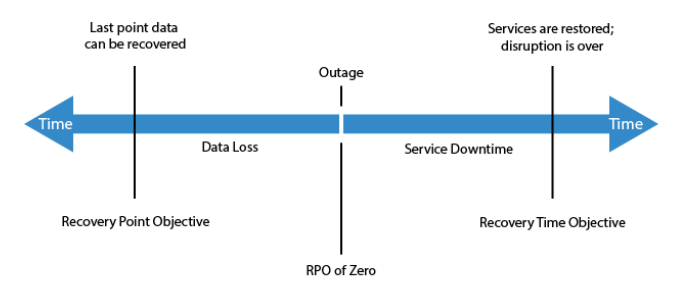
Risulta fondamentale riflettere sulla strategia di backup da adottare in funzione delle nostre esigenze di servizio partendo da due elementi fondamentali: quanti dati siamo disposti a perdere a fronte di un crash e in quanto tempo dobbiamo tornare in servizio. Queste tempistiche sono definite attraverso i due acronimi RPO e RTO:
- Recovery Point Objective (RPO) è il periodo massimo tollerabile per quanto riguarda la perdita di dati. Definisce sostanzialmente quanti dati possono essere persi a causa di un disastro. L'obiettivo definito per questo KPI ha un impatto sull'implementazione dei backup.
- Recovery Time Objective (RTO) è il tempo massimo che abbiamo a disposizione per ripristinare il sistema.
Nella strategia di backup sarà necessario capire poi se in caso di necessità di ripristino del database sarà sufficiente tornare ad una immagine del database indietro anche di diverse ore oppure se possiamo perdere solo pochi minuti di modifiche sul database, pertanto dovremo scegliere se configurare il database in ARCHIVELOG o in NOARCHIVELOG Mode.
In modalità ARCHIVELOG il redo log in uso, prima di essere sovrascritto, deve essere archiviato su una destinazione fisica preservando quindi tutte le transazioni che esso contiene affinché possano essere riapplicate in operazioni di recovery. In modalità NOARCHIVELOG, i redolog saranno semplicemente sovrascritti ciclicamente pertanto tutte le trx registrate andranno perse.
Di conseguenza:
- In NOARCHIVELOG non è possibile effettuare backup online del datbase e non si può recuperare il database ad uno specifico Point-In-Time che richiede l’applicazione dei redo logs;
- In ARCHIVELOG deve essere previsto dello storage aggiuntivo per la conservazione degli archivelog; può esserci un minimo (trascurabile) overhead dovuto ai processi archiver; gli archived redo logs devono essere mantenuti per un periodo di tempo possibilmente su storage esterno.
- Occorre determinare la frequenza dei backup.
Dipende dalla frequenza con cui vengono create e cancellate le tabelle, effettuate insert, delete e update nelle tabelle.
- Eseguire i backups prima e dopo eventuali modifiche strutturali
Creazione di nuove tablespace, aggiunta o rename di datafile nelle tablespace esistenti, modifica dei gruppi dei redologs.
- Backup di Tablespaces più usate.
- Backup dopo operazioni in NOLOGGING.
Operazioni di caricamento in direct path oppure creazione di tabelle e indici in NOLOGGING che non scrivono nei redologs.
- Export dei Dati ad integrazione dei bck e per maggior flessibilità.
- Mantenere copia della configurazione HW e SW del Server.
Esistono diversi motivi per conservare i backup più vecchi di datafile e archivelog:
- È necessario un backup precedente dei datafile e degli archivelog per eseguire la recover a un point-in-time precedente al backup più recente.
- Se il backup più recente è danneggiato, è comunque possibile ripristinare il database utilizzando un backup precedente e l'insieme completo degli archivelog a partire da quel backup precedente.
- Potrebbe essere necessario conservare una copia del database a scopo di archiviazione.
Alcuni esempi di restrore/recover per comprendere come effettuare le scelte di configurazione dei backup
Il backup di tipo FULL costituisce la base per ogni successivo ragionamento: la nostra catena dei backup parte sempre da qui.
In questo caso eseguiamo per esempio ogni giorno il backup full del database. Supponiamo sia schedulato a mezzanotte. Il nostro crash avviene alle ore 7 del mattino successivo al backup. Potremo ripristinare il nostro database alla mezzanotte dal backup della notte precedente, tutti i dati prodotti fino alle ore 7 andranno persi.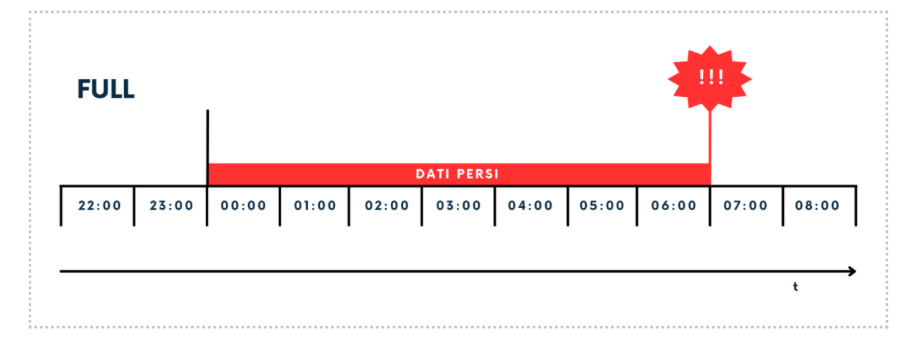
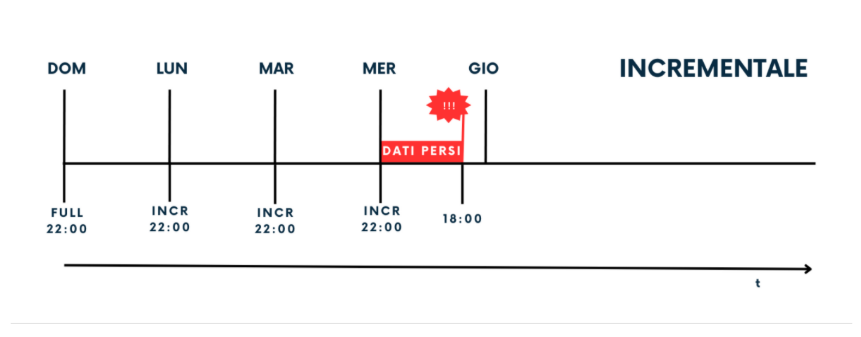
Immaginiamo adesso di avere una strategia di backup che consiste nell’eseguire un Full la Domenica alle ore 22 e nei successivi giorni della settimana, sempre alle ore 22, eseguire l’incrementale. Supponiamo che il crash avvenga alle ore 18 del giovedì. Oracle partirà dalla restore del full della Domenica, applicherà gli incrementali dal Lunedì al mercoledì ma tutti i dati prodotti dalle 22 del mercoledì alle 18 del giovedì andranno persi.
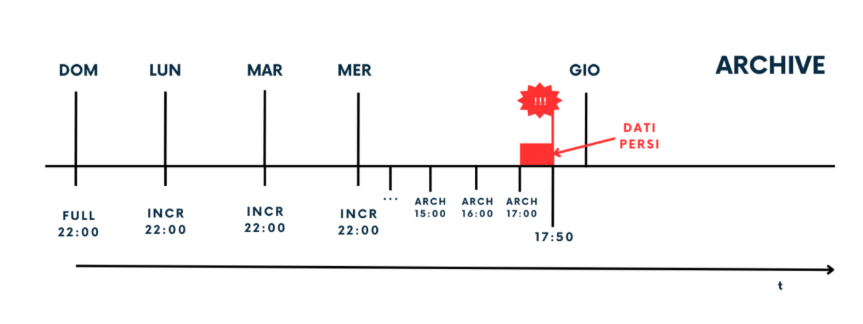
Immaginiamo adesso di avere una strategia di backup che consiste nell’eseguire un Full la Domenica alle ore 22 e nei successive giorni della settimana, sempre alle ore 22, eseguire l’incrementale. Avendo però il database in ARCHIVELOG, ho anche schedulato il backup degli archivelog ogni ora. Il nostro crash avviene alle 17.50 del giovedì. Oracle partirà dalla restore del full della Domenica, applicherà gli incrementali dal Lunedì al mercoledì e in ultimo gli archivelog prodotti dall’ultimo incrementale, quindi fino alle 17. Andranno persi soli i dati prodotti dalle 17 alle 17.50.
Naturalmente, la strategia di backup scelta deve tener conto sia delle esigenze di ripristino del database ma anche di questioni relative a costi, risorse, personale e altri fattori. Laddove possibile si suggerisce sempre di ridondare, duplicare le strutture dati più sensibili.
Il miglior insieme di ridondanza dovrebbe contenere:
- l’ultimo backup del controlfile e tutti i datafiles;
- tutti gli archivelog generati dopo l’ultimo backup;
- copia degli online redologs;
- copia del current controlfile;
- copia dei file di configurazione quali server parameter file, tnsnames.ora, and listener.ora
La prima regola per proteggere il nostro insieme di ridondanza è: mettere le copie di datafile, control file e redo logs su dischi separati.
di Anna Bruno, pubblicato il 21 maggio 2025
Ti serve aiuto con Oracle?
Richiedi subito un incontro conoscitivo e scopri come possiamo aiutarti ad ottenere il massimo dalla tua infrastruttura database.