Introduzione ai database non relazionali
Un database non relazionale, spesso chiamato NoSQL (Not Only SQL), è un tipo di sistema di archiviazione dei dati che non utilizza il modello tabellare tradizionale, tipico dei database relazionali. Mentre i database relazionali organizzano le informazioni in tabelle composte da righe e colonne, i database non relazionali offrono una maggiore flessibilità, permettendo di archiviare i dati in forme meno strutturate, come documenti, grafi, coppie chiave-valore o colonne larghe.
Differenza tra database relazionali e non relazionali
La differenza principale tra i due modelli risiede nella loro struttura e nel modo di gestire i dati. Nei database relazionali, è necessario definire uno schema rigido e ben definito prima che il database venga popolato con i dati, il che rende più complessa la gestione di informazioni non strutturate o soggette a modifiche frequenti. Al contrario, i database non relazionali permettono una struttura più dinamica, adattabile, e consentono di memorizzare informazioni anche se presentano campi variabili o di tipi differenti.
Nei prossimi paragrafi, forniremo alcune nozioni che vi aiuteranno a comprendere quando optare per un sistema piuttosto che per l’altro. In generale, però, un database non relazionale si dimostra particolarmente utile in contesti dove i dati sono complessi, variegati e non rientrano perfettamente nelle rigide tabelle relazionali. Ad esempio, per gestire grandi volumi di dati eterogenei o distribuiti, i database non relazionali forniscono scalabilità e prestazioni elevate, facilitando l’elaborazione di richieste in tempo reale. Inoltre, sono ideali per applicazioni moderne come le app web, mobile, IoT, social network, e analisi di Big Data, dove la flessibilità e l’adattabilità del modello di dati rappresentano un vantaggio significativo.
Database NoSQL e MongoDB
Tuttavia, è importante notare che i database NoSQL presentano anche alcune sfide. La loro permissività in termini di tipologia di dati immagazzinabili si traduce presto in una minore standardizzazione, un elemento che dichiara il database relazionale il sistema vincente per scenari in cui la coerenza dei dati è critica.
Uno dei database non relazionali più popolari in questo momento è indubbiamente MongoDB, il quale sfrutta un modello basato su documenti per gestire i dati in modo efficiente e flessibile. Nel paragrafo successivo vedremo più nel dettaglio cos'è MongoDB (e più in generale i database non relazionali) e come si differenziano dagli altri database. Verrà esposto anche un breve caso studio alla fine dell’articolo.
Il Modello Dati
I database non relazionali adottano un modello di dati orientato ai documenti, che differisce in modo sostanziale da quello dei database relazionali tradizionali. Nel modello documentale, i dati sono organizzati in documenti simili a JSON (si chiameranno BSON, una rappresentazione binaria ottimizzata), in cui ogni documento rappresenta un’entità autonoma e contiene dati strutturati come coppie chiavi-valore. Tale struttura consente di includere anche configurazioni nidificate, rendendo la rappresentazione molto flessibile e facilmente adattabile alle esigenze di applicazione.
Tipi di dati variabili
A differenza dei database relazionali – in cui è necessario definire uno schema rigido di tabelle e colonne previo inserimento dei dati – nei database non relazionali non richiedono una struttura obbligatoria. I documenti all’interno di una stessa collezione possono contenere campi diversi, ciascuno con tipi di dati variabili. Come anticipato nel paragrafo precedente, tale caratteristica rende i database non relazionali particolarmente adatti alla gestione di dati non strutturati (o semi-strutturati) come quelli prodotti da applicazioni web o da sistemi IoT, permettendo agli sviluppatori di modificare facilmente la struttura dei dati senza compromettere il funzionamento dell’applicazione.
Gestione delle relazioni
Un altro aspetto che contraddistingue un modello dati non relazionale è la gestione delle relazioni. Nei database relazionali, i dati tra tabelle diverse vengono collegati tramite chiavi esterne e recuperati con operazioni di join, che possono risultare costose in termini di prestazioni. Al contrario, nel modello documentale, i dati correlati possono essere incorporati nello stesso documento, consentendo di ridurre la necessità di join e di ottimizzare così le operazioni di lettura e scrittura. Soprattutto quando il volume di dati è massiccio, un database documentale è spesso in grado di essere più veloce per specifici tipi di query, ad esempio quando i dati sono poco strutturati o semi-strutturati.
Il modello documentale presenta, come dicevamo, anche alcune sfide. Tra le principali sono sicuramente l’assenza di coerenza forte, minore complessità di query, gestione e manutenzione più complessa.
Assenza di Coerenza Forte
L'assenza di coerenza forte nei database non relazionali, come quelli documentali, rappresenta una scelta progettuale orientata alla scalabilità e alla flessibilità. In questi sistemi, infatti, non viene garantita la coerenza immediata dei dati tra tutte le repliche, ma si privilegia una coerenza eventuale (eventual consistency). Questo significa che, dopo un aggiornamento, i dati potrebbero non risultare immediatamente identici su tutte le copie del database, ma convergeranno in uno stato coerente nel tempo. Tale approccio, pur sacrificando la coerenza forte a breve termine, permette di gestire meglio carichi distribuiti su larga scala e di rispondere a richieste di lettura e scrittura in modo più rapido. Tale compromesso è particolarmente vantaggioso – ancora una volta - in scenari in cui la disponibilità e la bassa latenza sono prioritarie rispetto alla coerenza assoluta, come nei sistemi di e-commerce, nei social network o nelle applicazioni di streaming, dove la rapidità di risposta è cruciale e leggere dati leggermente obsoleti non compromette l’esperienza dell’utente o l’integrità del sistema nel suo complesso.
Minore Complessità di Query
In questo paragrafo andiamo a trattare un tema che è simultaneamente un vantaggio ed una limitazione. Da un lato, la struttura semplice e flessibile dei documenti permette di evitare schemi rigidi e rende più rapida la modellazione di dati non strutturati o semi-strutturati. Tuttavia, questa semplicità comporta anche una significativa limitazione: le query avanzate, come quelle che richiedono join complessi o l’aggregazione di dati da più collezioni (tabelle nei database tradizionali), sono difficili da implementare o addirittura non supportate. Questo è dovuto al fatto che, per garantire prestazioni elevate e scalabilità, i database documentali evitano le operazioni intensive tipiche dei sistemi relazionali, spingendo gli sviluppatori a strutturare i dati in modo tale da minimizzare le relazioni complesse. Di conseguenza, per alcune applicazioni che necessitano di analisi trasversali e query sofisticate, i database documentali possono risultare meno adeguati rispetto a quelli relazionali, richiedendo workaround o una gestione manuale delle relazioni tra dati per ottenere risultati analoghi.
Gestione e Manutenzione
La flessibilità dei database documentali consente di avere schemi variabili e documenti con campi diversi all'interno della stessa collezione, ma questa libertà impone una maggiore attenzione nella gestione dei dati per garantire integrità e coerenza logica. Ogni modifica al modello dei dati, infatti, deve essere gestita manualmente, richiedendo spesso aggiornamenti di tutti i documenti o script personalizzati per migrazioni e trasformazioni. Inoltre, l’assenza di strumenti di query standardizzati e l'implementazione di meccanismi di coerenza distribuita possono complicare l'ottimizzazione delle prestazioni e il debug di eventuali problemi. La complessità aumenta ulteriormente in scenari distribuiti, dove la configurazione delle repliche e la gestione della consistenza eventuale richiedono una supervisione continua per prevenire incongruenze o perdita di dati. Di conseguenza, il mantenimento di un database documentale su larga scala può richiedere un impegno considerevole in termini sia di tempo che di risorse.
Caso Studio con MongoDB
In questo paragrafo portiamo una panoramica di un esempio pratico di architettura di un database documentale. In un’applicazione e-commerce, MongoDB è una scelta popolare per gestire il catalogo prodotti e i carrelli degli utenti. L’architettura di un sistema che utilizza MongoDB può essere pensata come segue:
- Front-end dell’applicazione: un’interfaccia utente che invia richieste API al back-end.
- Back-end: un server applicativo (ad esempio, Node.js) che gestisce le richieste del front-end, interagendo con il database.
- Database: MongoDB gestisce collezioni come utenti, prodotti e ordini. La collezione prodotti conterrà intuitivamente i dati di ciascun prodotto (nome, descrizione, prezzo, categoria), mentre la collezione carrelli mantiene lo stato del carrello di ogni utente.
Questo tipo di architettura consente una gestione flessibile e scalabile, dove MongoDB è ottimizzato per gestire rapidamente query sui dati dei prodotti, aggiornamenti in tempo reale dei carrelli e modifiche dinamiche nel catalogo prodotti.
Creazione di un Database

In MongoDB, i database e le collezioni possono essere creati automaticamente con l’inserimento di dati.
Inserimento di Documenti
Ricordiamo che in MongoDB i documenti sono unità di dati flessibili e sono rappresentati in formato BSON. Di seguito mostriamo alcuni esempi di inserimento di documenti nelle collezioni che abbiamo appena creato.
Ogni documento nella collezione prodotti rappresenta un singolo prodotto con le sue caratteristiche. L’inserimento di un documento può avvenire tramite il comando insertOne() per un singolo documento, o insertMany() per inserire più documenti alla volta.

Nome, descrizione, prezzo, categoria, disponibilità e un sotto-documento specifiche che include dettagli tecnici.
L’uso di insertMany() permette di popolare rapidamente la collezione con più prodotti, ottimizzando i tempi di inserimento.

 Analogamente a quanto fatto per
collezione carrelli. Ricordiamo che questa collezione tiene traccia dei carrelli di ciascun utente, associando un carrello a un utente specifico. Ogni documento può contenere una lista di prodotti nel carrello e le relative quantità.
Analogamente a quanto fatto per
collezione carrelli. Ricordiamo che questa collezione tiene traccia dei carrelli di ciascun utente, associando un carrello a un utente specifico. Ogni documento può contenere una lista di prodotti nel carrello e le relative quantità.
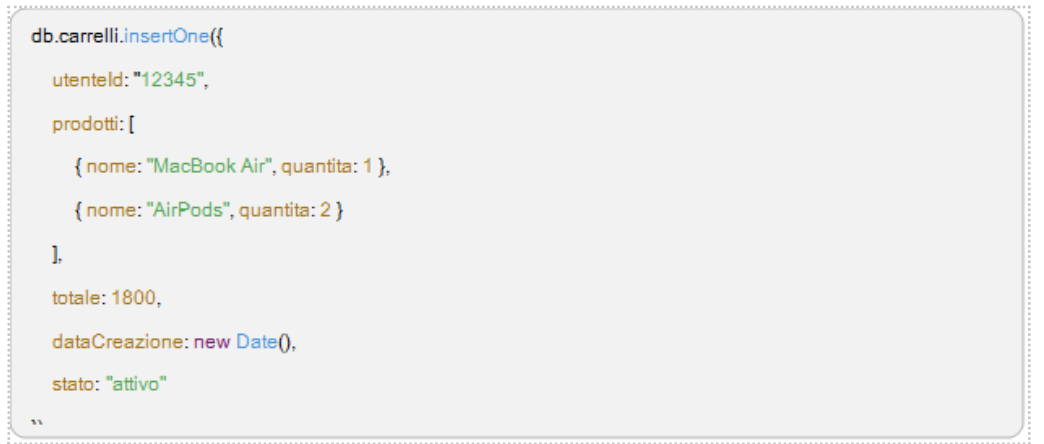
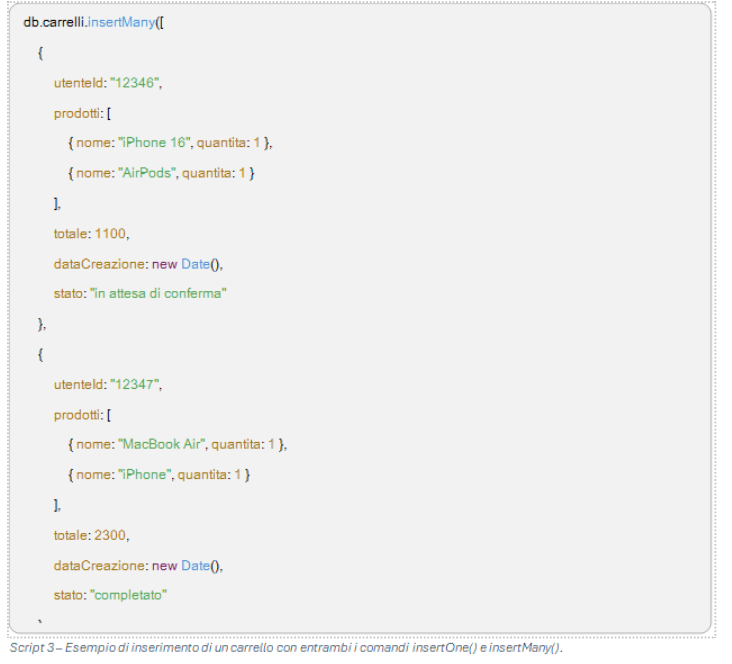
In questi esempi:
- Il campo utenteId identifica l’utente a cui è associato il carrello.
- prodotti è un array che contiene il nome e la quantità di ciascun prodotto.
- totale rappresenta il costo totale del carrello, utile per riepiloghi veloci.
- dataCreazione e stato tengono traccia della data di creazione e dello stato del carrello.
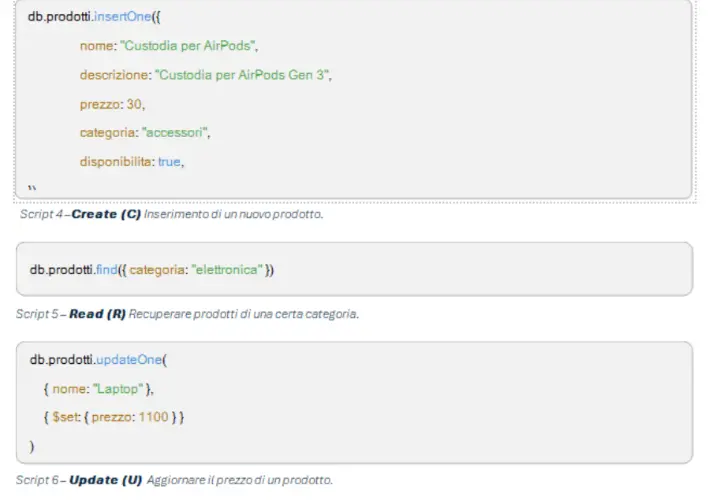
CRUD: Create, Read, Update, Delete

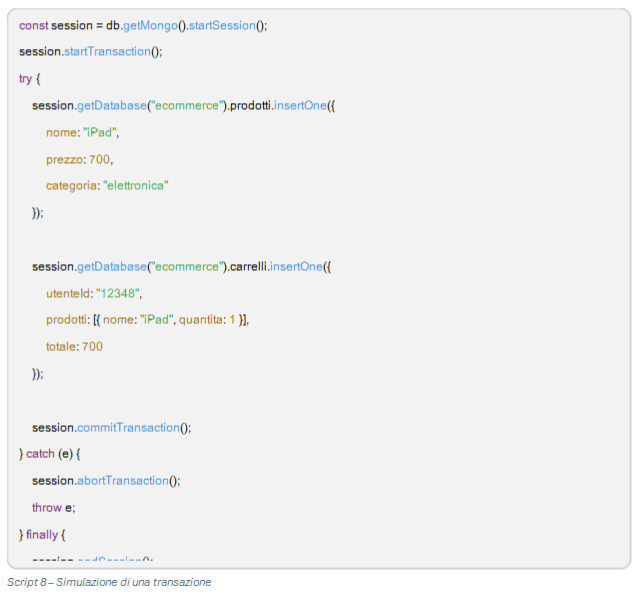
Gestione delle Transazioni
Per garantire consistenza nei dati, è necessario gestire transazioni. Una transazione consente di eseguire più operazioni di inserimento, aggiornamento o eliminazione come una singola unità logica, assicurando che tutte le operazioni vengano completate o annullate in caso di errore.
Conclusioni
In sintesi, MongoDB rappresenta una scelta efficace per la gestione di dati non strutturati o semi-strutturati, grazie alla sua flessibilità e capacità di scalare in modo orizzontale. Questa soluzione è particolarmente adatta in contesti come l’e-commerce, il social networking, e altre applicazioni che richiedono velocità di risposta e gestioni dinamiche di dati. Tuttavia, l'adozione di un database non relazionale richiede una valutazione attenta delle esigenze di coerenza e della complessità delle query. MongoDB, come evidenziato nel caso studio, si distingue per il modello documentale e il supporto alla scalabilità, ma implica anche la gestione di un'infrastruttura che supporti eventuali criticità legate alla consistenza e all’ottimizzazione delle prestazioni su larga scala.
di Matteo Ambrosini, pubblicato il 28 maggio 2025