Dopo aver visto cos'è e a cosa serve il log shipping in SQL Server, oggi vediamo i passaggi necessari per una corretta configurazione.
Configurare il log shipping
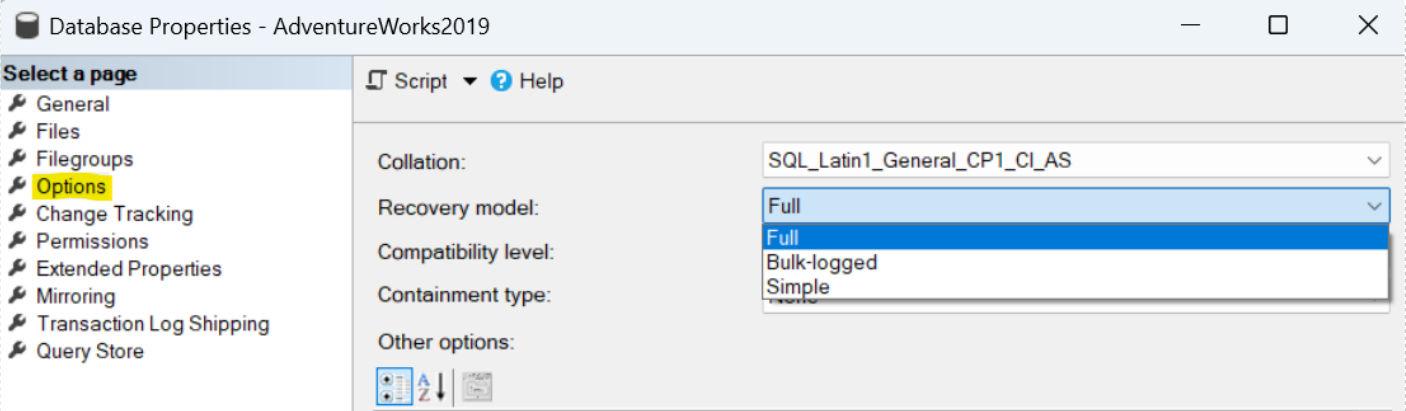
- Come prima cosa, dobbiamo assicurarci che il database primario sia in Full o Bulk-logged Recovery Model per poter eseguire il backup dei log del nostro database di interesse, eseguendo la seguente query:
In alternativa, possiamo farlo direttamente da SQL Server Management Studio entrando nelle proprietà del database.
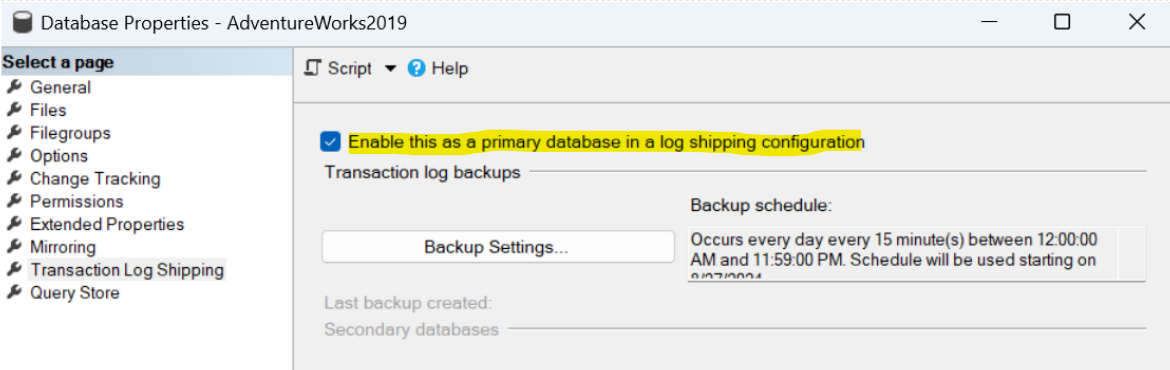
2. Da SQL Server Management Studio (SSMS), entriamo nelle proprietà del database primario, selezioniamo la tab ‘Transaction Log Shipping’ e mettiamo il check sulla voce ‘Enable this as a primary database in a log shipping configuration’:
3. Il passaggio successivo consiste nel configurare e decidere la frequenza con cui viene eseguito il backup dei log sul database primario. Clicchiamo su ‘Backup Settings' e ci apparirà la seguente finestra:
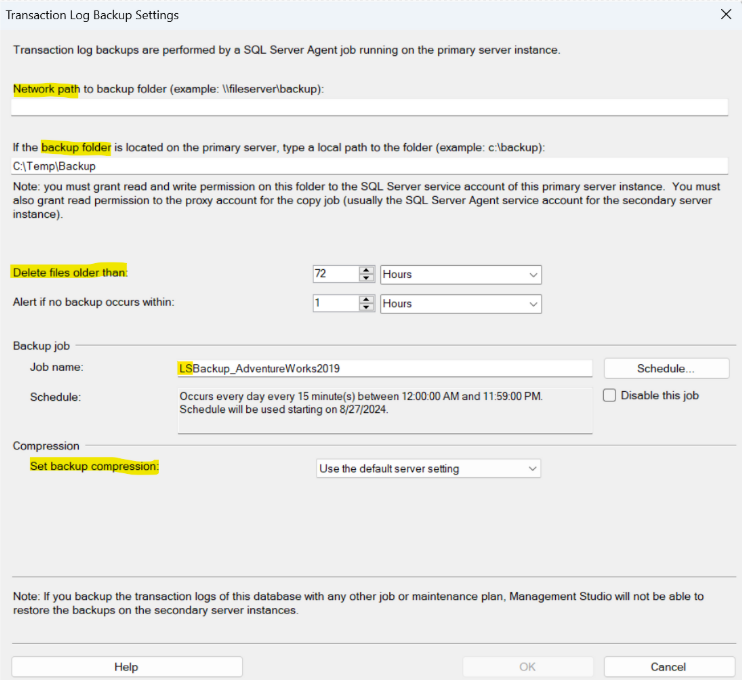
In base alla propria situazione, occorrerà decidere se usare un percorso di rete o una cartella presente nel server primario. In questo caso, scegliamo la seconda dato che sia l’istanza primaria che quella secondaria sono presenti sulla stessa macchina.
Nota: L’account del servizio dell’Agent del server primario deve avere permessi di lettura e scrittura in questa cartella e l’account del servizio che esegue la copia deve avere permessi di lettura.
A questo punto procediamo ad impostare un valore per il quale, se viene superato, il file di backup viene eliminato automaticamente. Dovremo valutare se i parametri di default vanno bene (di base un backup ogni 15 minuti è lo standard) e notare come i job relativi al Log Shipping vengono creati con la dicitura LS all’inizio del nome. Sceglieremo quindi se attivare la compressione (consigliata): in questo caso abbiamo lasciato il valore di default dell’istanza, cioè compressione attiva.
4. Ora è giunto il momento di configurare l’istanza ed il database secondario. Clicchiamo su ‘Add' e comparirà la seguente finestra:
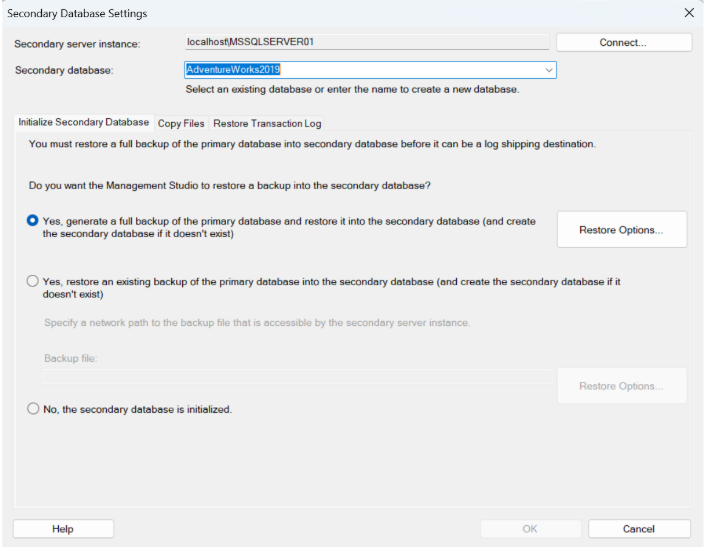
Clicchiamo su ‘Connect' e colleghiamoci all’istanza secondaria.
Una volta connessi SQL Server ci dà tre possibilità. La prima è quella di eseguire un backup al momento del database primario e ripristinarlo automaticamente sull’istanza secondaria. La seconda possibilità consiste nello specificare la locazione di un file di backup del database già esistente. La terza opzione è quella di non fare niente: saremo noi a dover andare sull’istanza secondaria e ripristinare il database. In questo caso, scegliamo la prima.
5. Passando alla seconda tab, ‘Copy Files', definiremo i parametri per creare il job di copia automatica dall’istanza primaria a quella secondaria dei log file di backup. Questo job verrà eseguito dall’Agent dell’istanza secondaria.
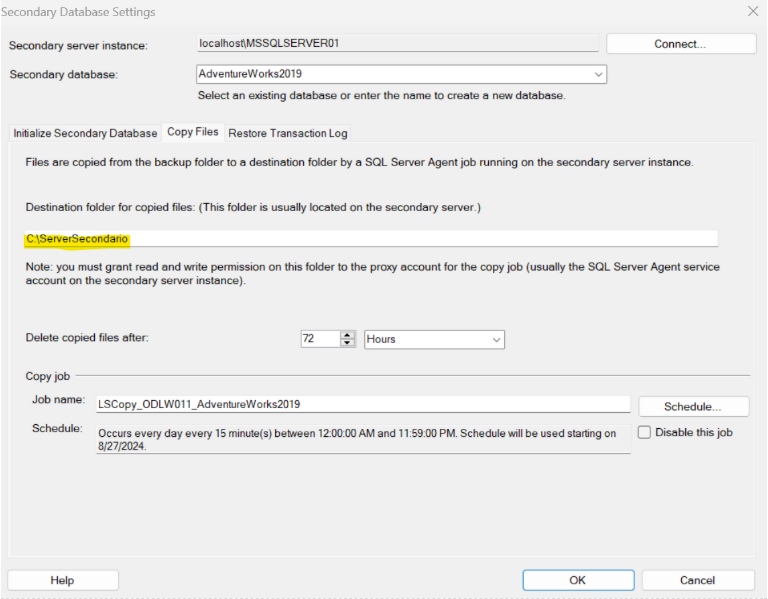
Nota. L’account del servizio dell’Agent del server secondario deve avere permessi di lettura e scrittura in questa cartella.
Nel nostro caso, dato che entrambe le istanze sono sulla stessa macchina, andiamo a definire un’altra cartella.
L’ultimo job da creare sull’istanza secondaria è quello di RESTORE:
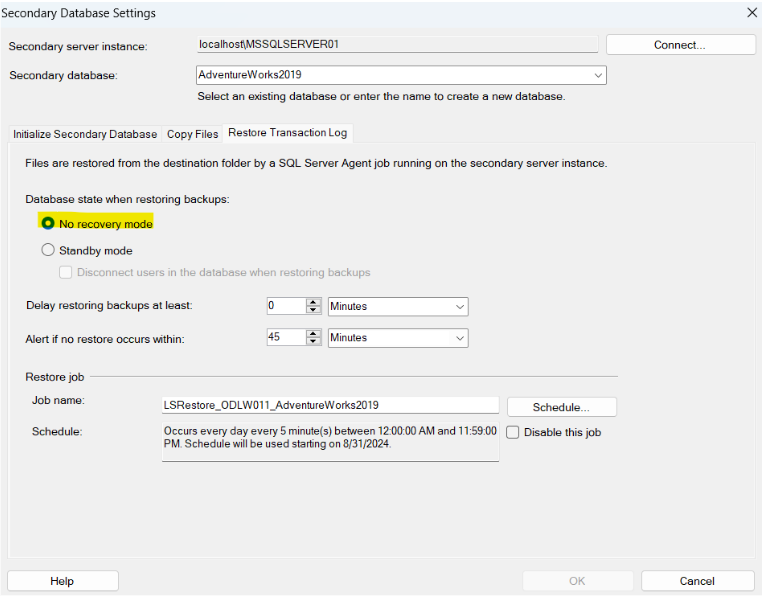
Connettiamoci all’istanza secondaria:
Abbiamo due scelte: No Recovery Mode e Standby Mode. Se si sceglie la prima significa che non si potrà leggere il database secondario. La seconda invece ci permetterà di effettuare operazioni di lettura sul database secondario. Nel nostro caso scegliamo No Recovery Mode.
Una volta fatto ciò, clicchiamo su ‘Ok'.
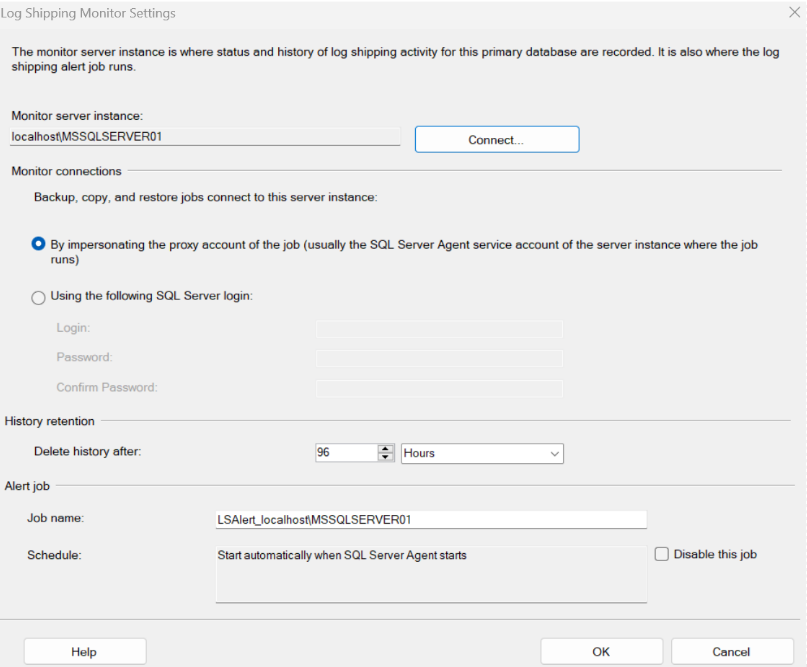
Questo passaggio è opzionale ma fortemente consigliato. Mettiamo la spunta su ‘Use a monitor server instance’ per creare un job per monitorare il corretto funzionamento del meccanismo di log shipping. Possiamo creare il job sull’istanza primaria, secondaria o un’altra ancora.
Clicchiamo su ‘Settings':

Diamo l’ok a questa finestra ed a quella principale, se tutto è stato configurato correttamente nel pop up che comparirà confermerà o meno il successo dell’operazione:
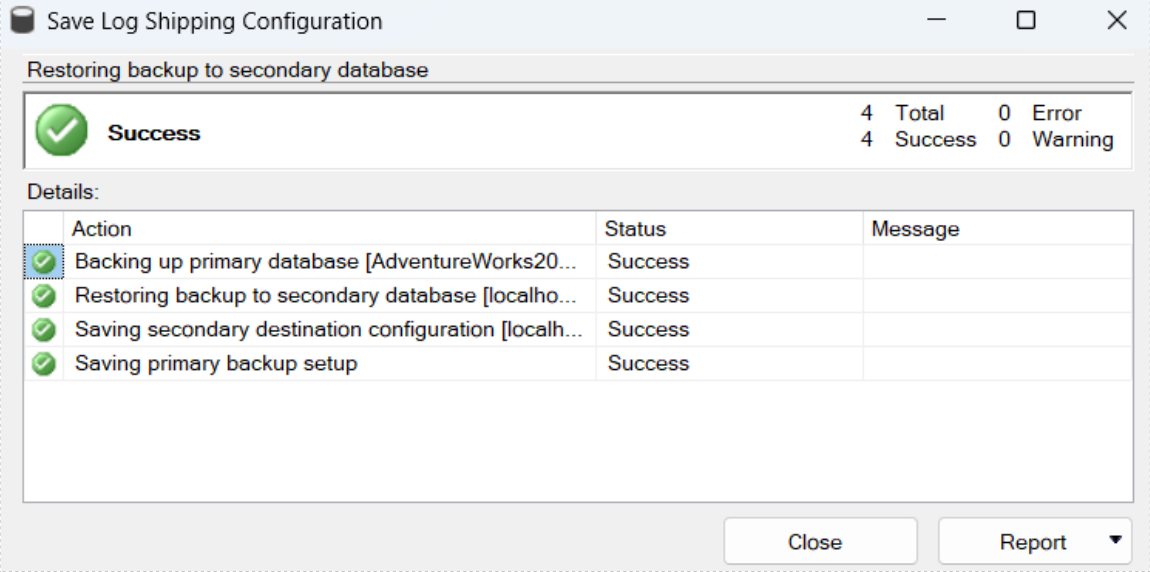
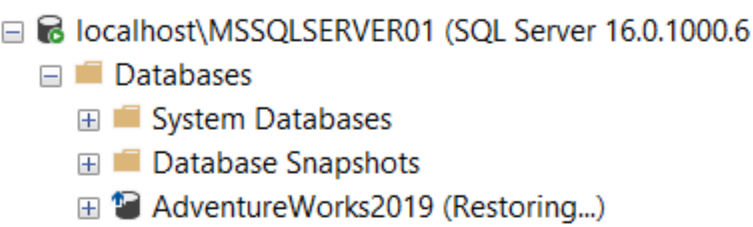
Nell’istanza secondaria il database è nello stato di restoring dato che abbiamo selezionato No Recovery Mode:
Conclusioni
Il Log Shipping rappresenta una soluzione solida e affidabile per il disaster recovery in SQL Server. È particolarmente utile in ambienti dove è necessaria una soluzione semplice, configurabile e con un impatto minimo sulle performance del server primario.
Tuttavia, come tutte le soluzioni di disaster recovery, presenta dei limiti che devono essere considerati in base alle esigenze specifiche dell'ambiente IT. È una soluzione ideale per chi necessita di un metodo efficiente per mantenere un database secondario aggiornato e pronto all'uso in caso di emergenza, pur senza la complessità e i costi associati ad altre tecnologie più avanzate.
di Nabil El Merzouki, pubblicato il 15 ottobre 2025

Rimani sempre aggiornato.
Iscriviti al blog Datamaze e rimani sempre aggiornato sul mondo dei dati.
Ricevi i nostri articoli direttamente nella casella mail, una volta al mese e senza spam.